代码拉取完成,页面将自动刷新
确定同步?
同步操作将从 duanchaojie/JavaCode 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。
克隆/下载
提示
下载代码请复制以下命令到终端执行
为确保你提交的代码身份被 Gitee 正确识别,请执行以下命令完成配置
使用 HTTPS 协议时,命令行会出现如下账号密码验证步骤。基于安全考虑,Gitee 建议 配置并使用私人令牌 替代登录密码进行克隆、推送等操作
Username for 'https://gitee.com': userName
Password for 'https://userName@gitee.com':
#
私人令牌
4年前
2年前
3年前
4年前
4年前
3年前
3年前
4年前
3年前
3年前
3年前
4年前
4年前
3年前
3年前
Loading...
[toc]
JavaCode
学习java过程中所敲的代码和笔记
JavaSE
- 通过Java的历史和演变对Java的应用范围有一定的了解,主体功能;
- 熟悉JDK、JRE、JVM的概念和区别;
- Java语言的注释、关键字、标识符的定义规则(不能数字开头、不能是关键字)、数据类型(基本:byte1 short2 int4 long8 floa4t double8 boolean1 char2,引用:类String 数组 接口);
- ASCII编码表也要了解:(0-48,9-57,A-65,Z-90,a-97,z-122);486597
- 常用DOS命令:(cls,ipconfig,cd ,dir,d:+回车);
- Java运算符:&& || !,三目运算符;
- Java数组(数组中的元素可以是
任何数据类型),以及基本数据类型(char \u0000)和引用数据类型的默认值,二维数据的在堆栈的内存分布情况,数组的工具类Arrays的常用方法:equals,fill,sort,toString; - 熟悉switch(byte|short|int|String|enum){case xx: yyy break },for循环(特别是两层嵌套)、while(条件){循环体;步长;},以及break和continue的用法和场景;
- 为什么数组获取长度用length,字符串获取长度用length();
- Object类中常用的方法:getClass(),hashCode(),equals(),clone(),toString(),finalize()垃圾回收前执行,wait(),notify(),notifyAll()线程相关;
- JVM会使用对象的hashcode值来提高对HashMap、Hashtable哈希表存取对象的使用效率。 2. ==判断的是内存地址;
- Object类的toString()方法默认返回该对象实现类的“类名+@+hashcode”值(十六进制hashcode);
- 常用API也要牢记:
- sc.nextInt(),sc.next()遇到空格结束,sc.nextLine();
random.nextInt(10) + 20;[20,30),不给值默认再int范围内随机生产; 3. 字符串常量池:程序中直接写上上引号的字符串,就存储在字符串常量池中。- 基本数据类型:== 比较的数值,引用数据类型:== 比较的是内存地址。
- String 专门给我们提供了一个方法用于字符串的比较:使用equals方法来完成字符串的比较。字符串使用equals比较的时候,比较是字符串里面的每一个字符。
- substring(int begin, int end); (从零开始)字符串截取, 包前不包后[ begin , end )
Arrays.sort(strArray, Collections.reverseOrder())降序排序(Arrays.sort()默认是升序);- Math.abs()绝对值,Math.ceil()向上取整,Math.floor()向下取整,Math.round()四舍五入;
- 泛型必须是引用数据类型
- ArrayList.add(e),ArrayList.add(idx,e),remove(idx),get(idx),set(idx,e),size()
- new Date(0)计算机元年1970,date.getTime()获取时间零点到当前时间的毫秒值
- new SimpleDateFormat(格式yyyy MM dd HH mm ss);sdf.format(Date),sdf.parse(String);
- Calendar.getInstance()获取Calendar实例
- System.currentTimeMillis(),
System.arraycopy(Object src,srcPos,Object dest,destPos,length)
- 静态代码块 > 非静态代码块 > 构造器,静态代码块只执行一次,非静态代码块,每次进入到当前类的时候都会执行一次。
- final修饰的引用数据类型,不能改变引用的地址能改变其属性值。
- 使用了final关键字修饰一个类那么这个使用final修饰的类不能有任何的子类但是可以拥有父类
- 重载:方法名相同,参数列表不同,方法返回值可以不同,权限修饰符可以不同。
- 子类方法的访问权限可以大于等于父类,返回值要小于等于父类;
- 只要创建子类的对象:父类的构造函数一定会被调用。如果父类中的构造方法被重写,一定要在父类中添加无参的构造方法,否则会报错(因为子类会调用);
- 在抽象的类中,可以重写也可以不重写接口中的抽象方法;
- 接口jdk8新增默认方法,解决接口升级所来的大量影响,jdk9增加了私有方法解决抽取公共代码,减少代码冗余,提高了代码的复用性。
- 多态:父类引用指向子类对象,前提是extends implements,属性编译和运行期-父类;行为:前期绑定-编译时绑定的时父类,后期绑定-运行时绑定的是子类;instanceof
- 方法里面的局部内部类不能使用权限修饰符,protected修饰的方法在不同包里面,只有子类对象可以调用。
- Optional,Optional.of(T),Optional.ofNullable(T);
- @Befer,@Test,@After
- 反射:Class.forName("全类名"),类名.class,对象名.getClass()三种获取的Class对象都是同一个;
- Class对象.getName()获取全类名,Class对象.getClassLoader()返回类加载器,Class对象.getInterfaces()获取实现的接口,Class对象.
getPackage()获取此类的包,也可以通过Class对象获取成员变量们,成员方法们,构造方法们; - 相同情况下使用StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。单线程操作字符串缓冲区下操作大量数据,使用StringBuilder;
- Lambda表达式格式:
(参数类型 参数名称) ‐> { 代码语句 }对象:: 实例方法名类:: 静态方法名类:: 实例方法名
枚举类的对象,多个对象之间用","隔开,末尾对象";"结束,Enum类.values()获取枚举类型的对象数组,Enum类.valueOf(String str)把一个字符串转为对应的枚举类对象;
JavaSE-集合
- Map接口{HashMap-->LinkedHashMap
、TreeMap和Properties},Collection接口{List接口(元素有序、元素可重复:ArrayList,LinkedList,Vector),Set接口(元素无序,而且不可重复:HashSet-->LinkedHashSet,TreeSet)} - Collection常用方法:add(E),clear(),remove(E),contains(E),isEmpty(),size(),toArray();
- Collection
接口与Map接口主要用于存储元素,而Iterator主要用于迭代访问(即遍历),Collection.iterator()获取迭代器,常用方法:it.hasNext(),it.next(); 泛型的好处:将运行时期的ClassCastException,转移到了编译时期变成了编译失败。泛型的上限:<? extends 类 >,泛型的下限:<? super 类 >;- List接口常用方法:add(idx,e),get(idx),remove(idx),set(idx,e)
- ArrayList集合元素增删慢,查找快;JDK1.7ArrayList
饿汉式,直接创建一个初始容量为10的数组;JDK1.8ArrayList像懒汉式,一开始创建一个长度为0的数组,当添加第一个元素时再创建一个始容量为10的数组。 - LinkedList(双向链表有prev和next变量)集合查询慢、但是方便元素添加、删除的集合。LinkedList常用方法:addFirst(e),addLast(e),getFirst(),getLast(),removeFirst(),removeLast(),pop()弹出一个元素,push(e),offer(e), isEmpty(),peek()获取第一个元素,但是不移除;
- 对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。对于新增和删除操作add(特指插入)和remove,LinkedList比较占优势,因为ArrayList要移动数据。
- Vector和ArrayList几乎是完全相同的,唯一的区别在于Vector是同步类(synchronized),属于强同步类,Vector每次扩容请求其大小的2倍空间,而ArrayList是1.5倍。常用方法:addElement(o),insertElementAt(o,idx),removeElement(o);
- ArrayList集合元素增删慢,查找快;JDK1.7ArrayList
- 可变参数:方法名(int... arr),只能放在参数列表的最后面,其实编译成的class文件将这些元素先封装到一个数组中。
- Collections 是集合工具类,常用方法:addAll(collection),shuffle(list)打乱,sort(list),sort(list,comparator比较器);
- ArrayList<Person(age,name)>根据age对Person进行排序:
- Person 实现 Comparable接口,重写compareTo方法,使用Collections.sort(list)进行排序;
- Collections.sort(list,new Comparator(){重写compare方法});
- HashSet存储的
元素是不可重复的,集合元素可以为null,线程不安全(底层HashMap); 当一个类有自己特有的“逻辑相等”概念,当改写equals()的时候,总是要改写hashCode(),根据一个类的equals方法(改写后),两个截然不同的实例有可能在逻辑上是相等的,但是,根据Object.hashCode()方法,它们仅仅是两个对象。所以复写equals方法的时候一般都需要同时复写hashCode方法。- TreeSet(底层使用红黑树结构存储数据)要实现定制排序,需要将实现Comparator接口的实例作为形参传递给TreeSet的构造器。
- Map接口中的常用方法:put(k,v),putAll(map),remove(k),clear(),get(k),containsKey(k),containsValue(v),size(),isEmpty()
- Map的三种遍历方式:
- map.keySet()-->keys(Set)-->map.get(key)
- map.values()-->Collection(value)-->iterator()-->iter.hasNext(),iter.next()
- map.entrySet() -->set<Map.Entry>-->Map.Entry-->getKey(),getValue()
- HashMap-->JDK1.7Entry数组-->JDK18Node(hash+key+value+next)数组
- TreeMap的key有自然排序Comparable和定制排序Comparator
- 与HashMap不同,Hashtable是线程安全的,不允许使用 null 作为 key 和 value
- HashTable的子类new Properties()的常用方法:==pros.load(InputStream/Reader)==,pros.setProperty(k,v),pros.getProperty(k),
System.getProperties方法就是返回一个Properties对象。stringPropertyNames():所有键的名称的集合。
- Stream API 提供了一种高效且易于使用的处理数据的方式(类sql),集合讲的是数据,Stream讲的是计算。Stream的操作三个步骤:创建Stream-->中间操作-->终止操作;
- 创建Stream:Collection.stream(),Collection.parallelStream(),Arrays.stream(数组),Stream.of(T... values),Stream.iterate(),Stream.generate()
- 中间操作:
- 筛选与切片:filter(lambda),distinct(n),limit(),skip(n)
- 映射:map(f),flatMap(f)
- 排序:sorted(自然排序),sorted(Comparator com定制排序)
- 终止操作:
- 匹配与查找:allMatch(f),anyMatch(f),noneMatch(f),findFirst(),findAny(任意一个),count(),max(Comparator),min(c),forEach(c)
- 归约:stream().reduce(0, Integer::sum)
- 收集:stream().collect(Collectors.toList())
JavaSE-IO流
-
java.io.File类是文件和目录路径名的抽象表示,开发路径使用/,File类构造器有:File(path/parent,child/File parent,String child) -
File类常用方法有:getAbsolutePath(),getPath(),getName(),length(字节),exists(文件/文件夹是否存在),isDirectory(),isFile(),createNewFile(不存在才创建),delete(),mkdir(),mkdirs(),list(返回文件/文件夹的名字),listFiles(返回的是File[])
- listFiles(FileFilter接口,重写accept(File)方法)
-
顶级父类们 输入流 输出流 字节流 字节输入流 InputStream 字节输出流 OutputStream 字符流 字符输入流 Reader 字符输出流 Writer -
下面我们分别从输入流和输出流来学习IO流:
-
输出字节流:OutputStream抽象类,常用方法:close(),flush(),write(byte[] b),write(byte[] b,int off从0开始,int len),write(int)
- FileOutputStream类,文件输出流,用于将数据写出到文件,构造方法FileOutputStream(File),FileOutputStream(str),FileOutputStream(File,true(append)),FileOutputStream(str,true(append)),回车符\r换行符\n
-
输入字节流:InputStream抽象类,close(),read()从输入流读取数据的下一个字节,read(byte[])
- FileInputStream类是文件输入流,从文件中读取字节。构造方法FileInputStream(File),FileInputStream(str),fis.read()的返回值是:
- 节流读取文本文件时,遇到中文字符时,可能不会显示完整的字符,因为一个中文字符可能占用多个字节存储。
-
输出字符流:Writer抽象类,常用方法:close(),flush(),write(int),write(char[]),write(char[] b,int off,int len),write(str)
- FileWriter类构造时使用系统默认的字符编码和默认字节缓冲区。FileWriter(File),FileWriter(str),
flush:刷新缓冲区,流对象可以继续使用。close:关闭流,释放系统资源。关闭前会刷新缓冲区。
- FileWriter类构造时使用系统默认的字符编码和默认字节缓冲区。FileWriter(File),FileWriter(str),
-
输入字符流:Reader抽象类,close(),read(),read(char[])
- FileReader构造函数FileReader(File),FileReader(str)
-
IO异常处理有两种方式,一种是throw Exception,一种是try...catch...finally
- JDK1.7优化后的try-with-resource语句,try(声明资源)会自动关闭
- JDK1.9try-with-resource语句的try(对象)中可以放置对象;
-
IO流还有缓冲流、转换流、序列化流:
-
缓冲流的基本原理,是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,等凑够了缓冲区大小的时候一次性写入磁盘,减少系统IO次数,从而提高读写的效率。
-
BufferedInputStream(InputStream),BufferedOutputStream(OutputStream),BufferedReader(Reader),BufferedWriter(Writer),其中bufferedReader.readLine()有特有方法读取一行文字,bufferedReader.newLine()写出行分隔符(换行),试试使用缓冲流赋值一个大文件;
-
字符集了解一下:ASCII字符集,GBK字符集(GBK编码),Unicode字符集(utf-8编码,utf-16编码,utf-32编码)
-
转换流只是字符流来说的因为字节流不会出现乱码问题:InputStreamReader(InputStream),InputStreamReader(InputStream,"GBK"),OutputStreamWriter(OutputStream),OutputStreamWriter(OutputStream,"utf8"),读取GBK编码的文件通过转换流输出未utf8编码的文件。
-
使用序列化流的对象需要满足两个条件:首先必须实现
java.io.Serializable接口,类的属性不能被transient关键字修饰(serialVersionUID序列化的版本号 表示序列化版本标识符的变量),序列化流ObjectOutputStream(OutputStream),常用方法writeObject(Object)将指定的对象写出。 -
反序列化流ObjectInputStream(InputStream),readObject()返回Object,如果能找到一个对象的class文件,我们可以使用readObject()进行反序列化操作。
-
打印流PrintStream,其实我们常用的
PrintStream out = System.out,打印流中有我们常用的print(),println()方法,PrintStream(String filename)输出到filename中,使用System.setOut(out)可以改变System.out.println()的输出流向; -
内存操作流:
- 字节内存流:
ByteArrayInputStream、ByteArrayOutputStream - 字符内存流:
CharArrayReader、CharArrayWriter - 内存操作流与基础流的区别:
输出(ByteArrayInputStream):程序 → ByteArrayInputStream→ 内存;输入(ByteArrayOutputStream):程序 ← ByteArrayOutputStream← 内存;
- 字节内存流:
-
// IO流部分必会写的内容 char[] chars = new char[1024]; int len; while ((len = fis.read(chars))!= -1){ fos.write(chars,0,len); } -
Java NIO和IO的主要区别:
- IO面向流,NIO面向缓冲区
- IO是阻塞IO,NIO是非阻塞IO,NIO使用选择器Selectors
-
Java NIO系统的核心在于:
- 通道(Channel)—传输
- 缓冲区(Buffer)—存储。
-
缓冲区:
Buffer(IntBuffer,ByteBUffer) 主要用于与NIO 通道进行交互,数据是从通道读入缓冲区,从缓冲区写入通道中的。标记、位置、限制、容量遵守以下不变式: 0 <= mark <= position <= limit后数据不能进行读写 <= capacity- ByteBuffer.allocate(capacity)--> ByteBuffer,常用方法:buff.put(byte[]),buff.flip()切换读取数据模式,buff.get(byte[]),buff.clear()清空缓冲区(被遗忘状态),buff.mark()标记,buff.reset()恢复mark位置,buff.hasRemaining()判断缓冲区中是否还有剩余数据
- ByteBuffer.allocate(n)非直接缓冲区——将缓冲区建立在 JVM 的内存中。
- ByteBuffer.allocateDirect()直接缓冲区——将缓冲区建立在物理内存中。可以提高效率。
-
通道Channel:
- Channel
表示IO 源与目标打开的连接。Channel接口--(FileChannel,DatagramChannel,SocketChannel,ServerSocketChannel)在 JDK 1.7 中的 NIO.2 增加XXXChannel.open()创建Channel,通过(RandomAccessFile、Socket、ServerSocket、DatagramSocket)FileInputStream.getChannel()也可以获取通道。 - channel.write(buff)将缓冲区的数据写到通道,channel.read(buff)将通道中的数据读到缓冲区。
- 理解通道分散读取与聚集写入的概念。通过write(ByteBuffer[]),read(ByteBuffer[])实现。
- Channel
-
传统的IO 流都是阻塞式的。也就是说,当一个线程调用read() 或write()时,该线程被阻塞,直到有一些数据被读取或写入,该线程在此期间不能执行其他任务。服务器端需要处理大量客户端时,性能急剧下降。 -
Java NIO 是非阻塞模式的。当线程从某通道进行读写数据时,若没有数据可用时,该线程可以进行其他任务。线程通常将非阻塞IO 的空闲时间用于在其他通道上执行IO 操作,所以单独的线程可以管理多个输入和输出通道。 channel.configureBlocking(false);开启非阻塞模式 -
选择器(Selector)是SelectableChannle 对象的多路复用器,Selector 可以同时监控多个SelectableChannel 的IO 状况,也就是说,利用Selector可使一个单独的线程管理多个Channel。Selector 是非阻塞IO 的核心。SelectableChannle -->-->SocketChannel,ServerSocketChannel,DatagramChannel
-
Selector.open() 方法创建一个Selector。向选择器注册通道:
SelectableChannel.register(Selector sel,int ops);当调用register(Selector sel, int ops) 将通道注册选择器时,选择器对通道的监听事件,需要通过第二个参数ops 指定SelectionKey.OP_READ...。 -
Java NIO 管道是2个线程之间的单向数据连接。 Pipe有一个source通道和一个sink通道。数据会被写到sink通道,从source通道读取。
-
NIO2-->new Paths.get()-->new Path(),Files工具类,JDK7新特性:自动资源管理(Automatic Resource Management, ARM),该特性以try 语句的扩展版为基础。
JavaSE-多线程
-
并发和并行的概念,当系统只有一个CPU时,线程会以某种顺序执行多个线程,我们把这种情况称之为线程调度。
-
进程和线程的概念,每个进程都有一个独立的内存空间,一个应用程序可以同时运行多个进程,是系统运行程序的基本单位,一个进程可以同时并发的运行多个线程
-
继承Thread重写run(线程执行体)方法,每一个执行线程都有一片自己所属的栈内存空间(联系JVM的虚拟机栈)Thread(),Thread(name),Thread(Runable,[name]),Thread(target)常用方法:getName()获取现场名称,start()--虚拟机调用该现场的run()方法,sleep(),currentThread()返回当前线程对象。
-
创建线程的三种方式:extends Thread(),实现Runable接口重写run()——适合多个相同的程序代码的线程去共享同一个资源,Thread(new FutureTask(Callable的子类——重写call()方法))
-
Java线程分为:守护线程,用户线程,Java垃圾回收就是一个典型的守护线程。
-
若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,否则的话就可能影响线程安全。
-
Java线程同步机制:
- 同步代码块synchronized(锁对象){}
- 锁对象可以是任意类型。
- 多个线程对象要使用同一把锁。
- 同步方法
对于非static方法,同步锁就是this。对于static方法,我们使用当前方法所在类的字节码对象(类名.class)。
- 锁机制。
- 同步代码块synchronized(锁对象){}
-
java.util.concurrent.locks.Lock 机制提供了比synchronized更广泛的锁定操作,同步代码块/同步方法具有的功能Lock都有,除此之外更强大,更体现面向对象。lock()加同步锁,unlock()释放同步锁。
-
不同的线程分别占用对方需要的同步资源不放弃,都在等待对方放弃自己需要的同步资源,就形成了线程的死锁,产生死锁的四个必要条件:
- 互斥条件
- 请求与保持条件
- 不可剥夺条件
- 循环等待条件
-
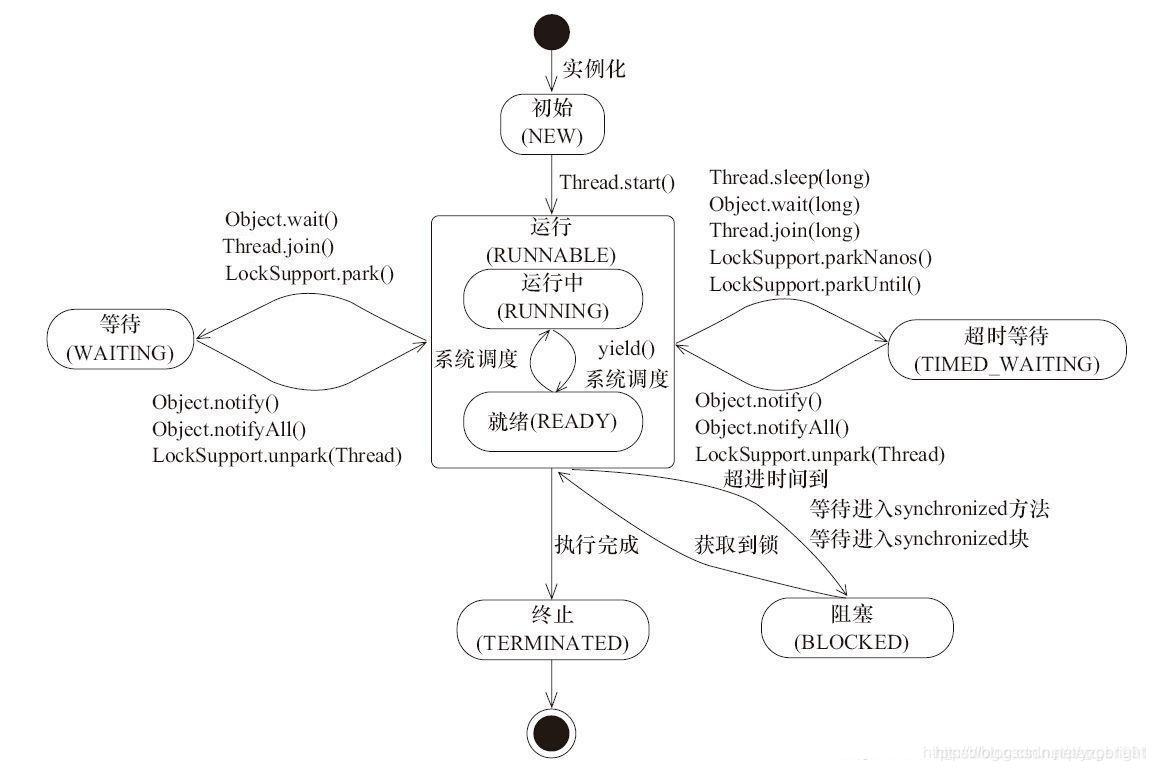
-
线程创建之后它将处于 NEW(新建) 状态,调用 start() 方法后开始运行,线程这时候处于 READY(可运行)状态。可运行状态的线程获得了 cpu 时间片后就处于 RUNNING(运行) 状态。
-
线程间通信——等待唤醒机制:线程A生产包子,线程B吃包子。wait方法与notify方法必须要由同一个锁对象调用,notifyAll()释放所通知对象的 wait set 上的全部线程。
-
线程池的好处:减低资源消耗,提高响应速度,提高线程的可管理性。
-
线程池接口是
java.util.concurrent.ExecutorService。要配置一个线程池是比较复杂的,尤其是对于线程池的原理不是很清楚的情况下,很有可能配置的线程池不是较优的,因此在java.util.concurrent.Executors线程工厂类里面提供了一些静态工厂,生成一些常用的线程池。官方建议使用Executors工程类来创建线程池对象。Executors类中有个创建线程池的方法如下:
-
Executors.newCachedThreadPool():创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。 -
Executors.newFixedThreadPool(n); 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。 -
Executors.newSingleThreadExecutor():创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序执行。 -
Executors.newScheduledThreadPool(n):创建一个定长线程池,支持定时及周期性任务执行。
阿里规约里面为什么线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险说明:Executors各个方法的弊端:
-
newFixedThreadPool和newSingleThreadExecutor:主要问题是推积的请求处理队列可能会耗费非常大的内存,甚至OOM)
-
newCachedThreadPool和newScheduledThreadPool:主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM。
-
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) { this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), defaultHandler); }
线程池有哪些参数,各代表什么意思?线程池中提供哪些队列种类和拒绝策略呢?
corePollSize:核心线程数。在创建了线程池后,线程中没有任何线程,等到有任务到来时才创建线程去执行任务。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中。maximumPoolSize:最大线程数。表明线程中最多能够创建的线程数量。keepAliveTime:空闲的线程保留的时间。TimeUnit:keepAliveTime参数的时间单位BlockingQueue:阻塞队列,存储等待执行的任务。参数有ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue可选。ThreadFactory:线程工厂,用来创建线程RejectedExecutionHandler:队列已满,而且任务量大于最大线程的异常处理策略。怎么使用线程池呢?ExecutorService.submit(new Runable(){重写run方法})从线程池中获取线程对象,然后调用MyRunnable中的run()
ExecutorService.shutdown()关闭线程池。
-
常用设计模式
类之间的关系: 依赖(我中有你你就是依赖我)、继承(空心实线)、实现(空心虚线)、关联(特殊的依赖)、聚合(空心菱形,整体与部分之前的关系,可分)与组合(不可分)。
单一职责原则接口隔离原则依赖倒转(倒置)原则:抽象不应该依赖细节,细节应该依赖抽象里氏替换原则:开闭原则:一个软件实体类,模块和函数应该 对扩展开放( 对提供方),对 修改关闭( 对使用方)。用抽象构建框架,用实现扩展细节。迪米特法则:一个对象应该对其他对象保持最少的了解合成复用原则:原则是尽量使用合成/聚合的方式,而不是使用继承。
代理模式
- 静态代理:代理对象和被代理对象都需要实现同一个接口,一旦接口新增方法,这两个对象都需要修改,违反开闭原则;
- 动态代理(JDK):利用Java反射实现 Proxy.newProxyInstance(ClassLoader loader,Class<?>[] interfaces,InvocationHandler h)
- 动态代理(Cglib)—SpringAOP底层使用:上述两种方式都需要被代理对象实现接口,使用Cglib需要引包,底层通过字节码处理框架ASM实现,只需要代理对象实现MethodInterceptor 接口重写 intercept 方法,会调用目标对象的方法。
- SpringAOP:
切面只是一个带有@Aspect注解的Java类,它往往要包含很多通知。切入点表达式:==execution(访问权限符 返回值类型 方法全类名(参数表))==@Before:前置通知,在方法执行之前执行@After:后置通知,在方法执行之后执行@AfterRunning:返回通知,在方法返回结果之后执行@AfterThrowing:异常通知,在方法抛出异常之后执行@Around:环绕通知,围绕着方法执行- @Pointcut("
execution(* *.*(..))") public void myPoint(){ } --> @Before(value = "myPoint()") - @Around("myPoint()") --> ProceedingJoinPoint是
JoinPoint的子接口,调用proceed()方法来执行被代理的方法。 - 最精确的
execution(public int cn.justweb.calculator.impl.CalculatorImpl.add(int,int)) - 最模糊的
execution(* *.*(..))千万别写,了解一下 - 用@Order(序号)注解,序号越小切面越先执行
- Spring的AOP是动态代理,为什么要导入AspectJ包?
- AspectJ在编译时就增强了目标对象,Spring AOP的动态代理则是在每次运行时动态的增强,生成AOP代理对象,区别在于生成AOP代理对象的时机不同,相对来说AspectJ的静态代理方式具有更好的性能,但是AspectJ需要特定的编译器进行处理,而Spring AOP则无需特定的编译器处理。
- @Aspect注解标识该类是切面类,spring-aop:AOP核心功能,例如代理工厂等等,aspectjweaver:支持切入点表达式等等
- 通知方法执行顺序:
- Spring4.3.13:
正常执行:环绕通知 -- @Before前置通知 -- 方法执行 -- 环绕通知 -- @After后置通知 -- @AfterReturning正常返回异常执行:环绕通知 -- @Before前置通知 -- @After后置通知 -- @AfterThrowing方法异常
- Spring5.2.8:
正常执行:环绕通知 -- @Before前置通知 -- 方法执行 -- @AfterReturning正常返回 -- @After后置通知 -- 环绕通知异常执行:环绕通知 -- @Before前置通知 -- @AfterThrowing方法异常 -- @After后置通知
工厂模式
- 大量的对象需要创建,并且具有共同的接口时,可以通过工厂模式进行创建。
- 简单工厂模式:Factory.getObj(objName)
- 工厂方法模式:Factory fty = new FactoryA/B();每个工厂都有一个子工厂,每个子工厂负责创建对应的对象(利用多态)。
- 静态工厂方法模式:在Factory中通过多个静态方法(方法数与对象种类一一对应),去创建对象
- 抽象工厂模式:工厂模式针对的是一个产品等级结构 ,抽象工厂模式针对的是面向多个产品等级结构的。前面的产品都实现同一个接口,而抽象工厂模式中则没有这样的限定。
单例模式
-
单例模式的应用:Runtime类(饿汉式),Spring的FactoryBean
-
饿汉式:静态对象初始化,静态方法返回对象,私有化的构造器
-
懒汉模式:静态对象定义但是不初始化,在静态方法中判断对象是否为null,来创建对象并返回,私有化构造器。(该模式多线程下不安全,可以给方法添加synchronized )
-
双重检查☆线程安全; 延迟加载; 效率较高:volatile(保证内存可见性--JMM,防止指令重排) 声明对象
public static Singleton getInstance() { if(instance == null) { synchronized (Singleton.class) { if(instance == null) { instance = new Singleton(); } } } return instance; } -
静态内部类:在静态内部类中声明静态对象,定义同步的静态方法返回对象实例(类装载的机制来保证初始化实例时只有一个线程)
装饰者模式
MySQL数据库
- DDL数据定义语言--建库建表,DML数据操纵语言,DQL数据查询语言,DML数据控制语言。
- where 语句在分组之前过滤数据,即先过滤再分组(分组后聚合)所以 where 后面不可以使用聚合函数而 having 子句在分组之后过滤数据,即先分组再过滤,所以having 后面可以使用聚合函数。limit offset(从0开始),length。MySQL字符串截取:right(str,length),left(str,length),substring()。
- MYSQL主键primary key约束:非空且唯一,唯一约束unique,非空约束not null default "dd",外键约束foreign key
- 为什么要有事务?保证数据的一致性。事务开启之后, 所有的操作都会临时保存到事务日志中, 事务日志只有在得到 commit 命令才会同步到数据表中,其他任何情况都会清空事务日志(rollback,断开连接)
- 事务的四大特性:ACID--原子性,一致性,隔离性,持久性
- 事务并发访问的三个问题:
- 脏读:一个事务读取到了另一个事务中尚未提交的数据
- 不可重复读:一个事务中两次读取的数据内容不一致
- 幻读:一个事务中两次读取的数据的数量不一致,这是 insert 或 delete 时引发的问题。
- 事务隔离级别:一个事务与其他事务隔离的程度,隔离级别越高,性能越差,安全性越高。
- 读未提交:
- 读已提交:可以避免脏读(Oracle Sqlserver)
- 可重复读:可避免脏读和不可重复读(Mysql)
- 串行化:可以避免脏读、不可重复读和幻读
- 数据表数据:
- 1NF表中每列不可再拆分,
- 2NF:在1NF的基础上,消除部分依赖,一张表只描述一件事情。
- A(学号,课程名称)—> 姓名 姓名部分依赖于
- 3NF:不产生传递依赖,表中每一列都直接依赖于主键。而不是通过其它列间接依赖于主键。
- 学号—>系名 系名—>系主任 ,系主任传递依赖于学号
- 索引:帮助数据库高效获取数据的数据结构,有序以某种方式引用指向数据。缺点:索引文件也不小,往往存在磁盘中,插入、更新、删除数据也需要维护索引。
- Mysql存储引擎:
- InnoDB引擎:支持BTREE(B树,B+树的结构)索引--数据有序范围查询,Full-text全文索引
- MyISAM引擎:BTREE,Full-text,R-tree索引
- InnoDB:行锁,支持事务,插入慢,内存和空间使用高
- MyISAM:表锁,不支持事务,插入速度快,内存和空间使用低
- 表锁:偏向MYISAM存储引擎,开销小,加锁快,不会出现死锁,锁定粒度大,发生锁冲突的概率最高,并发度低,适合多查询,少更新。
- 行锁:偏向InnoDB存储引擎,开销大,枷锁慢,会出现死锁,锁定粒度小,发生锁冲突的概率低,并发度高。
- 由于B+Tree只有叶子节点保存key信息,查询任何key都要从root走到叶子。所以B+Tree的查询效率更加稳定。MySql索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能。
- 为什么复合索引要遵循最左前缀法则?
- 视图就是一条SELECT语句执行后返回的结果集(Oracle中有物化视图的概念)。视图优势:简单,安全,数据独立。
- 存储引擎就是存储数据,建立索引,更新查询数据等等技术的实现方式 。存储引擎是基于表的,而不是基于库的。所以存储引擎也可被称为表类型。Oracle,SqlServer等数据库只有一种存储引擎。MySQL提供了插件式的存储引擎架构,比如说常用的InnoDB,MyISAM等。MySQL5.5之前的默认存储引擎是MyISAM,5.5之后就改为了InnoDB。
- 使用共享表空间存储, 这种方式创建的表的表结构保存在.frm文件中, 数据和索引保存在 innodb_data_home_dir 和 innodb_data_file_path定义的表空间中,可以是多个文件。
- 使用多表空间存储, 这种方式创建的表的表结构仍然存在 .frm 文件中,但是每个表的数据和索引单独保存在 .ibd 中。
- MyISAM 不支持事务、也不支持外键,查询和插入速度比InnoDB快(表锁)表结构.frm,数据myd,索引.myi分开存储。
- Mysql优化步骤:
- 慢查询日志 : 通过慢查询日志定位那些执行效率较低的 SQL 语句,用--log-slow-queries[=file_name]选项启动时,mysqld 写一个包含所有执行时间超过 long_query_time 秒的 SQL 语句的日志文件。
- show processlist命令查看当前MySQL在进行的线程,包括线程的状态、是否锁表等,可以实时地查看 SQL 的执行情况,同时对一些锁表操作进行优化。
- 分析什么原因导致SQL执行缓慢:使用explain/desc SQL获取执行的详细信息,如:表的链接类型(性能由好到差的连接类型为:system ---> const -----> eq_ref ------> ref -------> ref_or_null----> index_merge ---> index_subquery -----> range -----> index ------> all),索引实际使用情况等信息。
- 优化方法:利用索引,SQL语句优化,应用优化,查询缓存优化,内存管理优化。
- 索引优化:
- 建立合适的索引,复合索引。
- 避免索引失效的场景:索引列上进行运算、字符串不加单引号、where后使用or、以%开头的模糊查询、not in、is null、is not null、where后使用!= <> 参数@num =等会造成索引失效。
- 用exists 替换 in,尽量使用复合索引,不要使用select *
- SQL语句优化:
- 优化or条件,or两边都用索引。
- 应用优化:
- 使用连接池:对于访问数据库来说,
建立连接的代价是比较昂贵的,因为我们频繁的创建关闭连接,是比较耗费资源的,我们有必要建立数据库连接池,以提高访问的性能。- 维护一定数量的链接减少创建时间
- 更快的响应时间
- 统一的管理
- 减少对数据库的访问:
- 能一条SQL解决的事情就不要两条;
- 增加cache缓存层,现在主流的使用手段如:redis,MyBatis一二级缓存。
- 负载均衡:
- 利用某种均衡算法,将固定的负载量分布到不同的服务器上, 以此来降低单台服务器的负载,达到优化的效果。
- MySQL的
主从复制,实现读写分离,使增删改操作走主节点,查询操作走从节点,从而可以降低单台服务器的读写压力。 - 采用分布式数据库架构
- 使用连接池:对于访问数据库来说,
- 查询缓存优化:
- 客户端发送一条查询给服务器;
- 服务器先会检查查询缓存,如果
命中了缓存,则立即返回存储在缓存中的结果。否则进入下一阶段; - 服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划;
- MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询;
- 将结果返回给客户端,并缓存起来
- 内存管理优化:尽量多的内存分配给MySQL做缓存。
- MySQL日志:
- 错误日志.err
- 查询日志和慢查询日志都是默认关闭的
- 二进制日志记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但是不包括数据查询语句。此日志对于灾难时的数据恢复起着极其重要的作用,
MySQL的主从复制, 就是通过该binlog实现的。默认是关闭的,需要手动开启mysqlbin.000001 - binlog日志格式:STATEMENT(记录的都是SQL语句),Row(记录的是每一行的数据变更,而不是记录SQL语句),MIXED
- mysqlbinlog [-vv] logfile查看日志
- 日志删除:
Reset Master 指令删除全部 binlog 日志,删除之后,日志编号,将从 xxxx.000001重新开始 。- 执行指令
purge master logs to 'mysqlbin.******',该命令将删除******编号之前的所有日志。 - 执行指令
purge master logs before 'yyyy-mm-dd hh24:mi:ss',该命令将删除日志为 "yyyy-mm-dd hh24:mi:ss" 之前产生的所有日志 。 - 设置参数 --expire_logs_days=n ,此参数的含义是设置日志的过期天数。
- MYSQL主从复制:复制是指将主数据库的DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。MySQL支持一台主库同时向多台从库进行复制, 从库同时也可以作为其他从服务器的主库,实现链状复制。
- 步骤:
Master 主库在事务提交时,会把数据变更作为时间 Events 记录在二进制日志文件 Binlog 中。主库推送二进制日志文件 Binlog 中的日志事件到从库的中继日志 Relay Log 。slave重做中继日志中的事件,将改变反映它自己的数据。
- 优势:
主库出现问题,可以快速切换到从库提供服务。可以在从库上执行查询操作,从主库中更新,实现读写分离,降低主库的访问压力。可以在从库中执行备份,以避免备份期间影响主库的服务。
- 步骤:
Oracle数据库
- Oracle中使用rownum来进行分页, 这个是效率最好的分页方法。
- 支持多用户、大事务量的事务处理,数据安全性和完整性控制,支持分布式数据处理,可移植性
- Oracle实例:一个Oracle实例( Oracle Instance)有一系列的后台进程(Backguound Processes)和内存结构(Memory Structures)组成。
- Oracle表空间:表空间是Oracle 对物理数据库上相关数据文件( ORA 或者 DBF 文件)的逻辑映射。
- Oracle用户:用户是在表空间下建立的,用户:表空间=N:1。
- JDBC 驱动为:
oracle.jdbc.OracleDriver - 连接字符串( 瘦连接 ):
jdbc:oracle:thin:@IP:1521:orcl - 序列是 ORACLE 提供的用于产生一系列唯一数字的数据库对象。
- 表中的每一行在数据文件中都有一个物理地址,ROWID 伪列返回的就是该行的物理地址。 使用 ROWID 可以快速的定位表中的某一行。
- 在查询的结果集中,ROWNUM 为结果集中每一行标识一个行号,第一行返回 1, 第二行返回 2,以此类推。
- 索引是需要占据存储空间的,也可以理解为是一种特殊的数据。形式类似于 下图的一棵“树”,而树的节点存储的就是每条记录的物理地址,也就是我们提到的伪列( ROWID)。
- Oracle数据迁移:
- EXP和IMP是客户端工具程序,它们既可以在客户端使用,也可以在服务端使用。
- EXPDP和IMPDP是服务端的工具程序,他们只能在ORACLE服务端使用,不能在客户端使用。
- IMP只适用于EXP导出的文件,不适用于EXPDP导出文件;IMPDP只适用于EXPDP导出的文件,而不适用于EXP导出文件。
- 创建具有导入导出数据库的权限的用户,创建目录对象,建立与远程Oracle服务器的DB_link,执行expdp命令导出xxx.dmp文件,将文件上传到目标Oracle的服务器上,执行impdp命令(指导目录对象,SCHEMA映射关系,表空间映射关系)
非关系型数据库—Redis
-
关系型数据库和非关系型数据库有什么区别?
- 关系型数据库最典型的数据结构是数据表,而非关系型数据库数据格式可以是Key-Value形式、文档形式、图片形式等。
- 关系型数据库基于sql使用方便,支持事务,可以进行多个数据表的复杂管理操作,但是读写性能较差。
- 非关系型数据库不支持sql,虽然说数据结构比较复杂,但是读写性能高(无需sql层的解析)常与关系型数据库进行关联使用。
-
Redis是以key-value的形式存储的非关系型数据库,分布式的,开源的,水平可扩展的,为了保证效率,数据都是缓存在内存中,它也可以周期性的把更新的数据写入磁盘或把修改操作写入追加的记录文件中。
-
Redis支持的五种数据类型:字符串类型String,哈希类型hash,列表类型lisst,集合类型set,有序集合类型sortedset
- String:存储set key value ,获取get key,删除del key
- hash:底层使用哈希表结构实现数据存储key(String)-value(HashMap),主要是用来存放一些对象,把一些简单的对象给缓存起来。
- hash的成员比较少:value类似一维数组的方式来紧凑存储
- hash的成员较多:value则自动转成真正的HashMap
- 存储hset user name dd
- list支持重复元素:key(String)-value(LinkedList),双向链表可以支持双向查找和变量。
- 存储:lpush listname 1 2 3,rpush listname 1 2 3
- 获取:lrange listname 0 -1
- 删除:lpop/rpop listname
- set不允许重复元素key(String)-value(Set),存储sadd setname 1 1 2 2,获取smembers setname,删除srem setname
- 内部实现是一个value永远为null的HashMap,实际就是通过计算hash的方式来快速排重。
- sortedset:元素不允许重复,根据score从小到大排序。存储zadd key(score value)可以由多个,获取 zrange key start end 删除 zrem key value
- 内部使用HashMap(score)和跳跃表(skiplist)来保证数据的存储和有序。
- keys * 查询所有的键,type key,del key
-
Redis持久化方式RDB(默认-定时快照方式)和AOP(基于语句追加文件的方式)的区别:
- RDB:默认方式,不需要进行配置,默认就使用这种机制
- AOF:日志记录的方式,可以记录每一条命令的操作。可以每一次命令操作后,持久化数据在一定的间隔时间中,检测key的变化情况,然后持久化数据。
- 相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积;
-
Redis可以通过 maxmemory 参数来限制最大可用内存,主要为了避免Redis内存超过操作系统内存,从而导致服务器响应变慢甚至死机的情况。
-
//使用Redis有哪些好处? a.单线程,利用redis队列技术并将访问变为串行访问,消除了传统数据库串行控制的开销 b.redis具有快速和持久化的特征,速度快,因为数据存在内存中。 c.分布式 读写分离模式 d.支持丰富数据类型 e.支持事务,操作都是原子性,所谓原子性就是对数据的更改要么全部执行,要不全部不执行。 f.可用于缓存,消息,按key设置过期时间,过期后自动删除 //缺点:缓存与数据库双写不一致,缓存雪崩,缓存穿透
JVM
-
懂得JVM内部的内存结构、工作机制,是设计高扩展性应用和诊断运行时问题的基础,也是Java工程师进阶的必备能力。
-
JVM字节码包含了Java虚拟机指令集(或者称为字节码、Bytecodes)和符号表,还有一些其他辅助信息。
-
虚拟机可以分为系统虚拟机和程序虚拟机:典型代表就是Java虚拟机,Java技术的核心就是Java虚拟机(JVM) ,因为所有的Java程序都运行在Java虚拟机内部。 -
HotSpot VM是目前市面上高性能虚拟机的代表作之一。它采用解释器与即时编译器并存的架构。 -
Java编译器输入的指令流基本上是一种
基于栈的指令集架构,特点:指令集更小,编译器容易实现。不需要硬件支持,可移植性更好,更好实现跨平台。 -
了解JVM的发展历程:Classic VM(只有解释器,JDK1.4被淘汰)-->Exact VM(准确式内存管理,编译与解释混合工作)-->
HotSpot VM(JDk1.3开始,具有热点代码探测技术) -->JRockit VM(JDK89中整合到HostspotVM中)-->J9-->Taobao JVM(基于openJDK HotSpot VM发布的国内第一个优化、深度定制且开源的高性能服务器版Java虚拟机。创新的GCIH (GC invisible heap)技术实现了off-heap ,即将生命周期较长的Java对象从heap中移到heap之外,并且GC不能管理GCIH内部的Java对象,以此达到降低GC的回收频率和提升Gc的回收效率的目的,但是硬件严重依赖intel的cpu。)- 通过计数器找到最具编译价值代码,触发即时编译或栈上替换
- 通过编译器与解释器协同工作,在最优化的程序响应时间与最佳执行性能中取得平衡
-
字节码文件:-->类加载器子系统(加载,链接[验证,准备,解析],初始化)-->运行时数据区(方法区,堆空间,栈空间,PC寄存器,本地方法栈)-->执行引擎(解释器,JIT即时编译器)
- 加载阶段-双亲委派机制:
- 基础概念:引导类加载器(Bootstrap ClassLoader)和自定义类加载器(User-Defined ClassLoader)-->将所有派生于抽象类ClassLoader的类加载器都划分为自定义类加载器。
- 引导类加载器 Bootstrap ClassLoader:只加载包名为java、javax、sun等开头的类。
- 扩展类加载器 Extension ClassLoader:目录的jre/1ib/ext子目录(扩展目录)下加载类库
- 系统类加载器 App ClassLoader:加载环境变量classpath或系统属性java.class.path指定路径下的类库
- 工作原理:
- 如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行;
- 如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器;
- 如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式。
- 好处:避免类的重复加载,保证程序安全,防止核心API被随意更改。
- 沙箱安全机制:自定义String类,但是在加载自定义String类的时候会率先使用引导类加载器加载。
- 在JVM中表示两个class对象是否为同一个类存在两个必要条件:
- 类的完整类名必须一致,包括包名。
- 加载这个类的ClassLoader(指ClassLoader实例对象)必须相同
- 链接阶段--验证--解析--准备
- 验证阶段:
- 文件格式验证,元数据验证,字节码验证,符号引用验证。
- 解析阶段:
- 为
类变量分配内存并且设置该类变量的默认初始值,即零值。 这里不包含用final修饰的static,因为final在编译的时候就会分配了,准备阶段会显式初始化;
- 为
- 准备阶段:将常量池内的符号引用转换为直接引用的过程。
- 验证阶段:
- 初始化阶段:
- 执行类构造器方法
<clinit>()的过程:☆javac编译器自动收集类中的所有类变量的赋值动作和静态代码块中的语句合并而来。☆只有类变量才有方法。
- 执行类构造器方法
- 加载阶段-双亲委派机制:
-
我们把大厨后面的东西(切好的菜,刀,调料),比作是运行时数据区。而厨师可以类比于执行引擎。
-
线程私有(程序计数器,虚拟机栈[栈帧(局部变量表,操作栈,动态链接,方法返回地址)],本地方法栈;
-
线程间共享:堆、堆外内存(永久代或元空间[常量池,方法元信息,类源信息]、代码缓存) -
在Hotspot JVM里,每个线程都与操作系统的本地线程直接映射。
-
JVM系统线程:虚拟机线程,周期任务线程,GC线程,编译线程,信号调度线程。
-
程序计数器作用:
- 单线程:字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制。
- 多线程:用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
-
虚拟机栈(通过-Xss1m设置栈空间大小):栈帧的大小主要由局部变量表和操作数栈决定的。
- 局部变量表所需的容量大小是在编译期确定下来的,主要用于存储方法参数和定义在方法体内的局部变量这些数据类型包括各类基本数据类型、对象引用(reference),以及returnAddress类型。
- 当一个实例方法被调用的时候,它的方法参数和方法体内部定义的局部变量将会按照顺序被复制到局部变量表中的每一个变量槽slot(32位一个槽)上。
- 如果当前帧是由构造方法或者实例方法创建的,那么
该对象引用this将会存放在index为0的变量槽Slot处,其余的参数按照参数表顺序继续排列。 - HotSpot JVM的设计者们提出了
栈顶缓存(Tos,Top-of-Stack Cashing)技术,将栈顶元素全部缓存在物理CPU的寄存器中,以此降低对内存的读/写次数,提升执行引擎的执行效率。 - 动态链接:
在Java源文件被编译到字节码文件中时,所有的变量和方法引用都作为符号引用(symbolic Reference)保存在class文件的常量池里。- 动态链接的作用就是为了将这些符号引用转换为调用方法的直接引用。
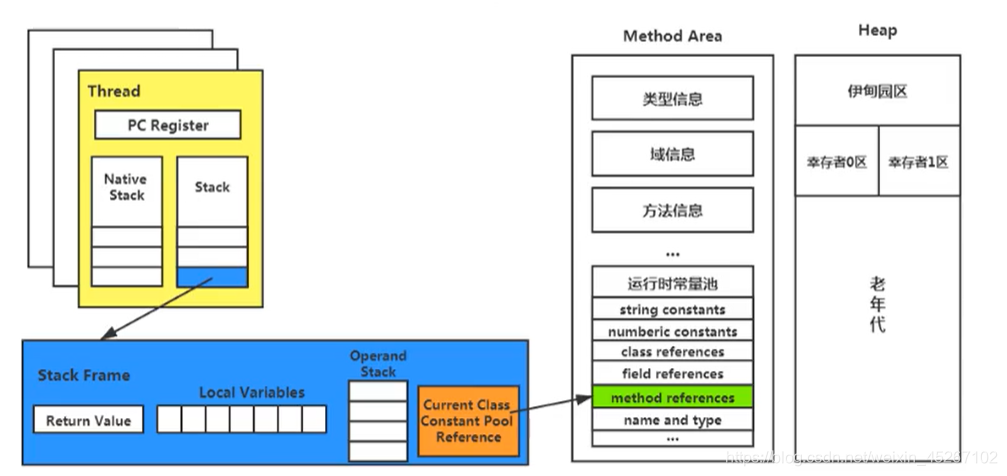
- 方法返回地址:存放调用该方法的pc寄存器的值
-
在Hotspot JVM中,直接将本地方法栈和虚拟机栈合二为一。 -
“几乎”所有的对象实例以及数组都应当在运行时分配在堆上。堆在逻辑上JDK1.7(新生代,老年代,永久代),JDK1.8(新生代,老年代,元空间)
-
通常会将-Xms(memory start)和-Xmx两个参数配置相同的值,其目的是为了能够在Java垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小,从而提高性能。
初始内存大小:物理电脑内存大小/64;最大内存大小:物理电脑内存大小/4;- -XX:+PrintGCDetails
-
年轻代(Eden:Survivor0:Survivor):老年代=1(8:1:1):2,from区、to区,复制之后有交换,谁空谁是to。。 -
当发现在整个项目中,生命周期长的对象偏多,那么就可以通过调整 老年代的大小,来进行调优。 -
几乎所有的Java对象都是在Eden区被new出来的。绝大部分的Java对象的销毁都在新生代进行了。(有些大的对象在Eden区无法存储时候,将直接进入老年代)IBM公司的专门研究表明,新生代中80%的对象都是“朝生夕死”的。
-
当老年代内存不足时,再次触发GC:
Major GC,进行老年代的内存清理。若老年代执行了Major GC之后,发现依然无法进行对象的保存,就会产生OOM异常 -
如果Survivor区满了后,不会触发MinorGC操作,将会触发
一些特殊的规则,也就是可能直接晋升老年代- 如果 Survivor 空间中相同年龄所有对象大小的总和大于 Survivor 空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,无需达到要求的年龄。
-
当年轻代空间不足时,就会触发Minor GC
-
出现了Major GC,经常会伴随至少一次的Minor GC,如果Major GC后,内存还不足,就报OOM了。
-
由Eden区、survivor space0(From Space)区向survivor space1(To Space)区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小。会触发Full GC -
70%-99%的对象是临时对象。
-
分代的唯一理由就是优化GC性能
-
大对象直接分配到老年代,因为如果在from/to间来回复制消耗性能。
-
TLAB,也就是为每个线程单独分配了一个缓冲区。- JVM为每个线程分配了一个私有缓存区域,它包含在Eden空间内
- 尽管不是所有的对象实例都能够在TLAB中成功分配内存,但JVM确实是将TLAB作为内存分配的首选(联想对象的创建过程)
- 默认情况下TLAB是开启的,TLAB空间的内存非常小,
仅占有整个Eden空间的1%
-
JDK6 Update 24之后的规则变为只要老年代的连续空间大于新生代对象总大小或者历次晋升的平均大小就会进行Minor GC,否则将进行Full GC。
-
如果经过逃逸分析(Escape Analysis)后发现,一个对象并没有逃逸出方法的话,那么就可能被优化成栈上分配。
-
逃逸分析的基本行为就是
分析对象动态作用域:当一个对象在方法中被定义后,对象只在方法内部使用,则认为没有发生逃逸,则可以在栈上分配。- 当一个对象在方法中被定义后,它被外部方法所引用,则认为发生逃逸。例如作为调用参数传递到其他地方中。
- 开发中能使用局部变量的,就不要使用在方法外定义。
- 逃逸分析无法保证逃逸分析的性能消耗一定能高于他的消耗。
-
Person(方法区) person(Java栈) = new Person()Java堆;方法区主要存放的是 Class,而堆中主要存放的是实例化的对象。
-
在jdk7及以前,习惯上把方法区,称为永久代。jdk8开始,使用元空间取代了永久代,并且元空间存放在堆外内存中。,使用永久代容易出现OOM,因为永久代的空间大小不好配置。元空间使用本地内存。 -
内存泄漏就是 有大量的引用指向某些对象,但是这些对象以后不会使用了,但是因为它们还和
GC ROOT有关联,所以导致以后这些对象也不会被回收,这就是内存泄漏的问题。- 如果是内存泄漏,
可进一步通过工具查看泄漏对象到GC Roots的引用链。于是就能找到泄漏对象是通过怎样的路径与GC Roots相关联并导致垃圾收集器无法自动回收它们的。掌握了泄漏对象的类型信息,以及GC Roots引用链的信息,就可以比较准确地定位出泄漏代码的位置。
- 如果是内存泄漏,
-
方法区:它用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等。
-
JDK1.6及以前 有永久代,静态变量存储在永久代上 JDK1.7 有永久代, 但已经逐步 “去永久代”,字符串常量池,静态变量移除,保存在堆中JDK1.8 无永久代,类型信息,字段,方法,常量保存在本地内存的元空间,但字符串常量池、静态变量仍然在堆中。
前端-HTML
-
明白Web,网页,网站,Web前端,后端,Html(超文本标记语言),CSS(层叠样式表),JavaScript(直译式脚本语言,是一种动态类型、弱类型、基于原型的语言,内置支持类型。),TypeScript,浏览器内核,字符集(编码解码)等概念;
<!--首先要有文档头DOCTYPE,指示 web 浏览器关于页面使用哪个 HTML 版本进行编写的指令。--> <!DOCTYPE html> <!--html根标签,head头部,body主体内容--> <html lang="en"><!--lang="zh-cn"--> <head> <meta charset="UTF-8"> <title>网页的标签</title> <stype> </stype> </head> <body> <a href="http://www.itbuild.cn">超链接(默认是_self)...</a> <a href="http://www.itbuild.cn" target="_blank">超链接...</a><!--在新页面中打开--> <a href="http://www.itbuild.cn" targe="_self">超链接...</a> <p>段落标签1</p> <p>段落标签2</p> <h1>标题标签h1</h1> <h6>标题标签h6</h6> <h7>标题标签h7(正常文本)</h7> <div>div双标签</div> <font color="blue">字体标签</font> <textarea cols="4" rows="4">文本域标签</textarea> <strong><b>加粗的新老标签</b></strong> <em><i>倾斜新老标签</i></em> <ins><u>下划线新老标签</u></ins> <del><s>删除新老标签</s></del> <!--但标签:hr红头线,br换行--> <hr> <br> <img src="/aaa/bbb/ccc.jpg"> <!--列表--> <ul> <li>无序列表</li> <li>无序列表</li> </ul> <ol> <li>有序列表</li> <li>有序列表</li> </ol> <dl> <!--dl中只能是dt和dd,是一个可描述的列表--> <dt>dt</dt> <dd>dd</dd> </dl> <table border="1px" width="100%"> <caption>表格的标题</caption> <thead><!--定义表格的头部,必须要有tr--> <!--表格标签--> <!--td thd的属性 rowspan=“x” x表示跨行数 colspan=“y” y表示跨列数 --> <tr> <th>表头1</th> <th>表头2</th> </tr> </thead> <tbody> <!--一行两列--> <tr> <td>a</td> <td>b</td> </tr> </tbody> </table> <!--表单form--> <form action="http://www.itbuild.cn" method="POST" name="表单名称"> <!--value 默认显示的文本--> <!--type 属性 可以决定了你属于那种input表单--> <!--name表单的名字, 这样,后台可以通过这个name属性找到这个表单。 页面中的表单很多,name主要作用就是用于区别不同的表单。--> <input type="text" value="单行文本输入框" name="duanduan"> <input type="password" value="密码输入框"> <input type="radio" value="单选按钮" checked="checked"> <input type="checkbox" value="复选框"> <input type="button" value="普通按钮"> <input type="submit" value="提交按钮"> <input type="reset" value="重置按钮"> <input type="image" value="图像形成按钮"> <input type="file" value="文件域"> <!--lable标签用于绑定一个表单元素, 当点击label标签的时候, 被绑定的表单元素就会获得输入焦点。--> <label> 用户名:<input type="radio" name="usename" value="请输入用户名"> </label> <textarea name="" id="1" cols="1" rows="1"></textarea> <!--select下拉列表--> <select name="" id="2"> <option value="">A</option> <option value="">B</option> <option value="">C</option> <option value="">D</option> </select> </form> </body> </html> -
表格的属性:
- cellspacing: 单元格之间的距离,默认的是 2px
- 如果设置为0px,还需要设置
border-collapse:collapse;相邻边框合并在一起。
- 如果设置为0px,还需要设置
- cellpadding:单元格的内边距,默认 1px
- width:设置表格的宽度
- height:设置表格的高度
- align:设置水平偏移 center ,left ,right
- border:设置表格的边框
- cellspacing: 单元格之间的距离,默认的是 2px
-
块级元素(div,h1-h6,hr,p,ul,li,ol,li,dl,dt,dd),行内元素(span,strong,del,ins,em,a),行内块级元素。
- display: inline/inline-block/block设置盒子的display样式去让盒子变成任何盒子的展示模式。
-
特殊字符:空格
前端-CSS&动画
-
了解CSS的三种书写方式:
- 行内式:
<div style="color: red; font-size: 12px;">青春不常在,抓紧谈恋爱</div> - 内部样式表:
<style>div{color: red;}</style> - 外部样式表:
<link rel="stylesheet" type="text/css" href="css文件路径">
- 行内式:
-
CSS选择器:有标签选择器div,类选择器
.类名(一个标签可以设置多个类属性,使用空格分隔),id选择器#id(元素的id值是唯一的,只能对应于文档中某一个具体的元素),通配符选择器*。- 复合选择器:后代选择器
.class h3,子元素选择器.class>h3,链接的伪类选择器(a:link a:visited a:hover a:active)lvha 的顺序不可变。 - 相临兄弟选择器:
元素+相邻兄弟元素; - 通用兄弟选择器:
元素~后面所有兄弟元素; - 群组选择器:
元素1,元素2; - 属性选择器:element[attribute] 为带有attribute属性的元素设置样式:li[title]选择拥有title属性的li标签。
li[title='ddaimm']为title='ddaimm'属性的元素设置样式。~=包含,^=以这个值开头,$=以这个为结尾,*=包含值得所有元素。
- CSS3结构类:
li:first-child{}选择li标签父元素的第一个孩子元素,如果该元素是li标签,那么触发下面的样式。li:last-child{}选择li标签父元素的最后一个孩子元素,如果该元素是li标签,那么触发下面的样式。li:nth-child(3),从1开始- li:nth-child(even)偶数,li:nth-child(odd)奇数;
- li:nth-child(2n+1)n的值是从0开始,每次加1,只能是n。
- li:nth-last-child(2)选择li标签父元素的倒数第二个孩子元素,如果该元素是li标签,那么触发下面的样式。
li:first-of-type,li:last-of-typeli:nth-of-type(3)匹配属于父元素的特定类型的第n个子元素- li:nth-of-type(even),li:nth-of-type(odd),li:nth-of-type(3n+1)
- li:only-child匹配属于其父元素的唯一子元素的每个元素
- li:only-of-type匹配属于其父元素特定类型的唯一子元素的每个元素
- span:empty匹配没有子元素(包括文本节点)的每个元素
- 否定选择器
ul :not(span)前面有空格,指的是ul标签下面的所有子标签。
- 复合选择器:后代选择器
-
通过CSS设置字体的样式:
font-size: 16px/1em;,font-family:“微软雅黑”;开发中可以使用unicode编码设置字体,font-weight: normal/bold/400/700;,font-style: normal/italic;- 字体样式的连写:
选择器 { font: font-style font-weight font-size/sline-height font-family;},不能更换顺序,但必须保留font-size和font-family属性。
- 字体样式的连写:
-
文本水平对齐方式
color: red/#90ee90/rgb/rgba;,文本水平对齐方式text-align: left/right/center;,行间距line-height: 16px/2em;,首行缩进text-ident: em;,文本的修饰text-decoration: none/underline/overline/line-through; -
元素模式 元素排列 设置样式 默认宽度 包含 块级元素一行只能放一个块级元素 可以设置宽度高度 容器的100% 容器级可以包含任何标签 行内元素一行可以放多个行内元素 不可以直接设置宽度高度 它本身内容的宽度 容纳文本或则其他行内元素 行内块元素一行放多个行内块元素 可以设置宽度和高度 它本身内容的宽度 - 行内元素为了照顾兼容性, 尽量只设置左右内外边距, 不要设置上下内外边距。
-
CSS背景的设置:
background-color: #90ee90;,background-image: none/url;url(多个url使用,分隔)不加引号,background-repeat: repeat/no-repeat/repeat-x/repeat-y;背景平铺,background-position: x|y(top/right/bottom/left/center);背景位置需要基于背景位置,background-attachment: scroll/fixed;背景附着;- 背景简写:background: 背景颜色 背景图片地址 背景平铺 背景滚动 背景位置;
background: transparent url(image.jpg) repeat-y scroll center top ;background: rgba(0,0,0,0.3);==背景==透明。- background-clip设置元素的背景(背景图片或颜色)是否延伸到边框border-box、内边距盒子padding-box、内容盒子下面content-box。
background-size:cover/contain;设置图片大小,cover默认查找最远边,contain默认查找最近边。
-
行高
line-height: x%/ypx;,基线和基线的距离; -
CSS三大特性:层叠性(长江后浪推前浪,前浪死在沙滩上),继承性(子承父业),优先级(谁的权重大,谁生效);
-
继承的权重是 0 标签选择器的权重是/元素选择器 1 类选择器的权重是 10 id选择器的权重是 100 行内样式的权重是 1000 !important 权重是 无穷大
-
-
盒子模型有元素的内容、边框(border)、内边距(padding)、和外边距(margin)组成。
- 边框:
border: 1px solid/dashed/dotted/none red;,还可以使用border-top/border-top-stype; - 内边距:
padding: 上% 右px 下% 左px;(一个值就是上右下左),如果没有给一个盒子指定宽度, 此时,如果给这个盒子指定padding, 则不会撑开盒子,相反如果设置了宽高盒子会被撑大。也可以使用padding: 上下内边距 左右内边距;,padding-left: 16px; 盒子的实际的大小 = 内容的宽度和高度 + 内边距 + 边框。- 外边距: 使用方法同padding,margin就是控制盒子和盒子之间的距离。
- 相邻块元素垂直外边距的合并,俩盒子垂直间距不是margin-bottom与margin-top之和 取两个值中的较大者这种现象被称外边距塌陷。
- 边框:
-
块级盒子水平居中:一、设置盒子的宽高;二、左右外边距设置atuo。盒子内的文字水平居中是
text-align: center;, 而且还可以让行内元素和行内块居中对齐。 -
盒子模型布局稳定性:
优先使用 宽度 (width) 其次 使用内边距(padding)再次 外边距(margin)。 -
扩展:
- 去除有序列表和无序列表的默认样式:
list-style:none; - 圆角边框:
border-radius: 16px/50%; - 盒子阴影:
box-shadow: 5px 5px 3px 4px rgba(0, 0, 0, .4);box-shadow:水平阴影 垂直阴影 模糊距离(虚实) 阴影尺寸(影子大小) 阴影颜色 内/外阴影;
- 去除有序列表和无序列表的默认样式:
-
盒子浮动float:
- CSS三种布局方式:标准流,浮动(让多个块级盒子一行显示),定位。
- 行内块(inline-block) 可以实现多个元素一行显示,但是中间会有空白缝隙,也不能实现以上第二个问题,盒子左右对齐;
- 元素的浮动
float:left/right/none;是指设置了浮动属性的元素会:脱离标准普通流的控制,移动到指定位置。 - float属性会改变元素display属性。浮动元素会生成一个块级框,生成的块级框和我们前面的行内块极其相似。
- 浮动元素与父盒子的关系:子盒子的浮动参照父盒子对齐,不会与父盒子的边框重叠,也不会超过父盒子的内边距。
浮动只会影响当前的或者是后面的标准流盒子,不会影响前面的标准流。- 清除浮动
clear:left/right/both;主要为了解决父级元素因为子级浮动引起内部高度为0 的问题。清除浮动之后, 父级就会根据浮动的子盒子自动检测高度。父级有了高度,就不会影响下面的标准流了- 是W3C推荐的做法是通过在浮动元素末尾添加一个空的标签例如
<div style="clear:both"></div>,或则其他标签br等亦可。 - 父级添加
overflow:hidden/auto/scroll;属性方法。就是内容增多时候容易造成不会自动换行导致内容被隐藏掉,无法显示需要溢出的元素。 - :after 方式为空元素额外标签法的升级版,好处是不用单独加标签了。减轻了浏览器的渲染负担,所以考虑使用伪元素 :after 来代替这个空白标签,因为清除浮动需要在浮动元素后面,所以不可以使用 :before ,对 :after 设置 content:"" ,并使其 display:block 成为块级元素后 clear:both 来清除浮动。
- 是W3C推荐的做法是通过在浮动元素末尾添加一个空的标签例如
-
定位:将盒子定在某一个位置 自由的漂浮在其他盒子(包括标准流和浮动)的上面 。
定位 = 定位模式 + 边偏移- 定位模式:
position:static/relative/absolute/fixed;静态/相对/绝对/固定定位。- 静态定位就是无定位的意思;
相对定位是元素相对于它原来在标准流中的位置来说的。原来在标准流的区域继续占有,后面的盒子仍然以标准流的方式对待它。绝对定位是元素以带有定位的父级元素来移动位置,完全脱标 —— 完全不占位置,父元素没有定位,则以浏览器为准定位(Document 文档)。子绝父相——子级是绝对定位,父级要用相对定位,因为==父级要占有位置,子级要任意摆放==。
固定定位是绝对定位的一种特殊形式,完全脱标,只认浏览器的可视窗口——浏览器可视窗口 + 边偏移属性来设置元素的位置。
- 绝对定位的盒子居中:
position:absolute;left:50%;margin-left:-weigthpx; z-index层叠等级属性可以调整盒子的堆叠顺序,正整数、负整数或0,默认值是 0,数值越大,盒子越靠上;z-index只能应用于相对定位、绝对定位和固定定位的元素。
-
box-sizing: content-box/border-box;默认是content-box -
伪元素:div::first-line第一行,div::first-letter第一个字母,div::before,div::after在元素的内容前/后面插入新内容,常与content配合使用,div::selection用于设置浏览器中选中文本后的背景色与前景色。
- 伪元素无法通过JS获取其DOM,无法通过浏览器直接查看,伪元素默认是 inline
-
边框圆角(块元素,行内块元素,行内元素):
border-radius:%/px;,一个值4个角都生效。可以制作八卦图,大风车。- 两个值:左上角和右下角 右上角和左下角
- 三个值:左上角 右上角和左下角 右下角
- 四个值:左上角 右上角 右下角 左下角
-
文字阴影text-shadow,可以实现文字阴影,浮雕文字,文字描边,文字排版等。
/*text-shadow: 水平方向的偏移量,垂直方向的偏移量,模糊程度,阴影的颜色。*/ text-shadow:6px -6px 2px lightgreen,7px -7px 1px lightpink; /*字间距*/ letter-spacing: 10px; /*描边*/ -webkit-text-stroke: 4px deeppink; /*文字方向:ltr/rtl*/ direction:rtl; -
盒子阴影:box-shadow,可以实现立体球等效果。
/* box-shadow:水平方向的偏移量,垂直方向的偏移量,模糊程度,扩展程度,盒子阴影的颜色,inset 内阴影*/ box-shadow:5px -5px 10px 10px rgba(88,255,99,1) inset; /*不设置inset为外阴影,为一个盒子设置多给阴影使用“,”隔开*/ /*box-reflect : 倒影的方向(above below left right ) 倒影与元素之间的距离 倒影效果(线性渐变)*/ -webkit-box-reflect:below 10px linear-gradient(0deg,rgba(0,0,0,1),rgba(0,0,0,0)); /*横向拉动长短*/ resize:horizontal; /*纵向拉动长短*/ resize:vertical; /*拉动横向和纵向长短*/ resize:both; -
背景模糊(图片文字都可以)
filter:blur(5px); -
渐变gradient:
- 线性渐变
background-image:linear-gradient(方向,颜色,颜色);- 方向有:to right,to top,to top right,to bottom left,60deg等;
background: linear-gradient(red 10%,blue 20%,green 30%,yellow 40%);background:linear-gradient(to right,red 25%, blue 25%, blue 50%,green 50%, green 75%, yellow 75%);
- 径向渐变
background:radial-gradient(circle/ellipse,颜色,颜色);
- 线性渐变
-
过度
transition: property duration timing-function delay;时间顺序不能乱,其他参数位置不限,如果想给多个属性添加不同的过度,参数之间使用逗号分开。transition-property: none/all/property;transition-duration: 2s/2000ms;- transition-timing-function:
- linear:线性过渡(匀速)cubic-bezier(0,0,1,1)
- ease:平滑过渡(慢--快--慢),默认值 cubic-bezier(0.25,0.1,0.25,1)
- ease-in:慢--快 cubic-bezier(0.42,0,1,1)
- ease-out:快--慢 cubic-bezier(0,0,0.58,1)
- ease-in-out:慢--快--慢 cubic-bezier(0.42,0,0.58,1)
transition-delay: 2s/2000ms;
-
变换transform:
- 2D变换:变换基点transform-origin:水平方向 垂直方向,可以使用top和%、px;
- 旋转rotate:
transform: rotate(45deg);如果是正数,顺时针旋转,如果是负数,逆时针旋转。 - 平移translate:
transform: translate(xpx,ypx)/translateX(xpx)/translateY(ypx); - 缩放scale:
transform: scale(0.5,2)/scale(0.5)/scale(2); - 倾斜skew:
transform: skew(xdeg,ydwg)/skew(xdeg)/skew(ydeg);
- 旋转rotate:
- 3D变换:开启3D变换
transform-style: preserve-3d;,一般对父元素设置。- 设置景深:
perspective: 300px;实现元素在3D空间中的近大远小的效果,景深值越大,效果越不明显,越接近2d变换。 - 变换基点transform-origin:默认是
50% 50% 0,Z轴只能使用具体的长度。 - 景深中心点:
perspective-origin: top right;改变观察者视角 - 改变观察者视角:
backface-visibility: visible/hidden;(默认值:可见) - 变换设置:
- rotateX():指对象在X轴上的旋转角度(变换基点: 50% 50% 0)
- rotateY():指对象在Y轴上的旋转角度(变换基点: 50% 50% 0)
- rotateZ():指对象在Z轴上的旋转角度(变换基点: 50% 50% 0)
- translateZ():指对象在Z轴上面的平移(变换基点: 50% 50% 0)
- scaleZ():指对象在Z轴上面的缩放(变换基点: 50% 50% 0)
- 设置景深:
- 2D变换:变换基点transform-origin:水平方向 垂直方向,可以使用top和%、px;
-
动画animation:
@keyframes animation-name{0%{}100%{}};,结合着变换和精灵图可以实现很多有意思的动画。animation-name: 动画名称;animation-duration: 5s;动画持续时间animation-timing-function:动画的过渡类型,处理可以设置一下内容还可以使用steps(x);- linear:线性过渡(匀速)
- ease:平滑过渡(0--慢--快--慢),默认值
- ease-in:慢--快
- ease-out:快--慢
- ease-in-out:慢--快--慢
animation-delay:2s;动画的延迟时间animation-iteration-count:infinite;动画循环次数animation-direction:normal/reverse/alternate/alternate-reverse;animation-play-state:paused/running;动画运行的状态animation-fill-mode:backwards/forwards/both;设置对象动画外的状态animation: name duration timing-function delay interation-count direction play-state;
-
伸缩盒子模型flex:flex布局原理就是通过给父盒子添加flex属性,来控制子盒子的位置和排列方式。开启flex布局:
display: flex;- flex容器的常用属性:
flex-direction: row/row-reverse/column/column-reverse;设置flex布局的主轴;justify-content: flex-start/flex-end/center/space-around/space-between;设置主轴上的子元素的排列方式;flex-wrap:nowrap/wrap;子元素是否换行,默认不换行;align-items: flex-start/flex-end/center/stretch;设置侧轴上的子元素的排列方式(只能在子元素单行时设置);align-content: flex-start/flex-end/center/space-around/space-between/stretch;设置侧轴上的子元素的排列方式(只能在子元素多行时设置)flex-flow: flex-direction flex-wrap;flex主轴金和子元素是否换行的复合属性;
- flex子项的常用属性:
flex: 2;flex属性定义子项目分配剩余空间,用flex来表示占多少份数默认是0;align-self: flex-start/flex-end/center;控制子项自己在侧轴上的排列方式;order: -1;属性定义项目的排列顺序,数值越小,排列越靠前,默认为0。
- flex容器的常用属性:
-
语义化标签布局:
-
多媒体:
- 音频audio:
- 视频video:
-
Canvas



前端-JavaScript
-
什么是JS:一种
直译式解释脚本语言,动态类型、弱类型、基于原型的语言,内置支持类型。 -
JS的组成:ECMA,BOM,DOM
-
声明变量使用:var、val、let;变量命名同Java,Python声明变量直接写。在JS中使用var定义的变量,会存在变量提升。
-
JS数据类型:number,string.length,boolean,==object==,undefined,Symbol,Null
-
JS运算符和赋值运算符同Java,JS特有的比较运算符
==等于 ===等值类型 != !==,注意for循环中的声明变量,声明数组var arr = [1,2,3,4,"hahah"],数组的遍历arr.length,JS也支持面向对象。 -
常用函数parseInt(),console.log(),typeof(),instanceof(),document.write()
-
// 自定义函数 function haha(param1,param2){ /*方法体;*/ return xxx; } // 匿名函数 var haha = function(param1,param2){}() -
JSON(JavaScript Object Notation, JS 对象简谱)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
-
JS常用对象:
- JSON对象:
var zhangsan={"name":"张三","age":19,"sex":"男"}- JSON.parse(.json)转成JSON对象
- JSON.stringify(json对象)解析成json串
- Date对象,其中一些getXXX()方法;
- Math对象的常用方法:abs(),ceil(),round(),max(),min(),pow(2,3),random()[0,1)
- 字符串常用方法:charAt(),concat(),indexOf(),lastIndexOf(),replace(),substring(),split(),trim(),toLocaleLowerCase()
- 数组常用方法:push(),pop(),unshift(),reverse(),slice(),splice(),sort(fun)
- JSON对象:
前端-jQuery
前端-Vue
Maven
- package和install的区别?package是把jar打到本项目的target下,而install时把target下的jar安装到本地仓库,供其他项目使用
Web基础
-
明白JDBC整个流程,软件架构C/S和B/S结构的区别,以及静态资源和动态资源的概念,还有网络通信的三要素:
-
传输协议:规定了数据传输的规则。
- tcp协议:有连接,安全协议,三次握手。速度慢。 文件传输。
- udp协议:无连接,不安全协议。 直播,点播,广播。
-
ip地址:电子设备(计算机)的在网络中的唯一标识。
-
端口号:应用程序在电子设备(计算机)中的位置标识。
-
-
明白web服务器(安装了服务器软件的计算机),web服务器软件(接收用户的请求,处理请求,响应结果)的概念。常见的web服务器软件有:tomcat中小型,weblogic大型,websphere大型,JBoss大型。
-
tomcat和nginx的区别:
- nginx常用做静态内容服务和代理服务器,直接外来请求转发给后面的应用服务器;
- tomcat更多用来做一个应用的容器;将项目直接放到webapps文件夹中,可以直接放web应用文件,也可以放web应用的war包,tomcat启动时,会自动解压war包;
-
servlet接口,定义了Java类如何能够被浏览器访问到的规范。自定义类(servlet对象在第一次被访问到的时候创建,load-on-startup>=0时tomcat启动时创建)实现servlet接口重写
- init()方法:servlet对象被创建的时候,执行init方法。
- service()方法:每次访问servlet的时候,service方法就会被调用一次;
- destory()方法:只有正常关闭服务器的时候,才会执行destory方法,一般用来关闭资源;
- 编写web.xml中的servlet和servlet-mapping
- 执行原理:
- 浏览器发送请求:http://localhost:8080/hello
- 服务器接收到请求后,解析url地址,要去找到对象的servlet,然后执行他的service方法
- 服务器在加载web.xml的时候,会去解析servlet-mapping中的url-pattern的路径
- 如果找到的对应的路径,根据路径找到servlet-class的全类名
- tomcat将当前的class文件加载到内存中,并且创建它的对象
- 调用servlet中的service方法
-
Servlet3.0(WEB3.0)算是比较新的Servlet技术了,对应版本JDK7,Servlet3.0的配置步骤:定义一个servlet类,实现servlet接口,重写方法,使用注解配置(可以省略web.xml不写):
@WebServlet(urlPatterns = {"/student","/student1"},loadOnStartup = 1) @WebServlet("/mm") public class HelloServlet implements Servlet{ //重写Servlet方法 }
Spring
SpringMVC
MyBatis
MyBatisPlus&Jpa
SpringBoot
SpringClould
是什么?
怎么用?
怎么用好?
为什么这样用就好呢?
软件架构
- Spring
- SpringMvc
- MybatisPlus
- SpringDataJpa
- SpringDataElasticsearch
- RabbiteMQ
- SpringBoot
- SpringCloud
- .......
大数据技术之Spark生态圈
安装教程
git clone https://gitee.com/duanchaojie/java-code.git
参与贡献
- Fork 本仓库
- 新建 Feat_xxx 分支
- 提交代码
- 新建 Pull Request
Java学习路线

☆
GNU GENERAL PUBLIC LICENSE
Version 3, 29 June 2007
Copyright (C) 2007 Free Software Foundation, Inc. <http://fsf.org/>
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU General Public License is a free, copyleft license for
software and other kinds of works.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
the GNU General Public License is intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users. We, the Free Software Foundation, use the
GNU General Public License for most of our software; it applies also to
any other work released this way by its authors. You can apply it to
your programs, too.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
To protect your rights, we need to prevent others from denying you
these rights or asking you to surrender the rights. Therefore, you have
certain responsibilities if you distribute copies of the software, or if
you modify it: responsibilities to respect the freedom of others.
For example, if you distribute copies of such a program, whether
gratis or for a fee, you must pass on to the recipients the same
freedoms that you received. You must make sure that they, too, receive
or can get the source code. And you must show them these terms so they
know their rights.
Developers that use the GNU GPL protect your rights with two steps:
(1) assert copyright on the software, and (2) offer you this License
giving you legal permission to copy, distribute and/or modify it.
For the developers' and authors' protection, the GPL clearly explains
that there is no warranty for this free software. For both users' and
authors' sake, the GPL requires that modified versions be marked as
changed, so that their problems will not be attributed erroneously to
authors of previous versions.
Some devices are designed to deny users access to install or run
modified versions of the software inside them, although the manufacturer
can do so. This is fundamentally incompatible with the aim of
protecting users' freedom to change the software. The systematic
pattern of such abuse occurs in the area of products for individuals to
use, which is precisely where it is most unacceptable. Therefore, we
have designed this version of the GPL to prohibit the practice for those
products. If such problems arise substantially in other domains, we
stand ready to extend this provision to those domains in future versions
of the GPL, as needed to protect the freedom of users.
Finally, every program is threatened constantly by software patents.
States should not allow patents to restrict development and use of
software on general-purpose computers, but in those that do, we wish to
avoid the special danger that patents applied to a free program could
make it effectively proprietary. To prevent this, the GPL assures that
patents cannot be used to render the program non-free.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this
License. Each licensee is addressed as "you". "Licensees" and
"recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a "modified version" of the
earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based
on the Program.
To "propagate" a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices"
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work
for making modifications to it. "Object code" means any non-source
form of a work.
A "Standard Interface" means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
"Major Component", in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
"aggregate" if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, "normally used" refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
"Installation Information" for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered "further
restrictions" within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, "control" includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To "grant" such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. "Knowingly relying" means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is "discriminatory" if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Use with the GNU Affero General Public License.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU Affero General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the special requirements of the GNU Affero General Public License,
section 13, concerning interaction through a network will apply to the
combination as such.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU General Public License from time to time. Such new versions will
be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU General
Public License "or any later version" applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
state the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
<one line to give the program's name and a brief idea of what it does.>
Copyright (C) <year> <name of author>
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
Also add information on how to contact you by electronic and paper mail.
If the program does terminal interaction, make it output a short
notice like this when it starts in an interactive mode:
<program> Copyright (C) <year> <name of author>
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
This is free software, and you are welcome to redistribute it
under certain conditions; type `show c' for details.
The hypothetical commands `show w' and `show c' should show the appropriate
parts of the General Public License. Of course, your program's commands
might be different; for a GUI interface, you would use an "about box".
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU GPL, see
<http://www.gnu.org/licenses/>.
The GNU General Public License does not permit incorporating your program
into proprietary programs. If your program is a subroutine library, you
may consider it more useful to permit linking proprietary applications with
the library. If this is what you want to do, use the GNU Lesser General
Public License instead of this License. But first, please read
<http://www.gnu.org/philosophy/why-not-lgpl.html>.
举报
请认真填写举报原因,尽可能描述详细。
请选择举报类型
误判申诉
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。




尝试更多
代码解读
代码找茬
代码优化