代码拉取完成,页面将自动刷新
确定同步?
同步操作将从 寻找距离/iread 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。
克隆/下载
提示
下载代码请复制以下命令到终端执行
为确保你提交的代码身份被 Gitee 正确识别,请执行以下命令完成配置
使用 HTTPS 协议时,命令行会出现如下账号密码验证步骤。基于安全考虑,Gitee 建议 配置并使用私人令牌 替代登录密码进行克隆、推送等操作
Username for 'https://gitee.com': userName
Password for 'https://userName@gitee.com':
#
私人令牌
Loading...
基于uniapp的小说在线采集阅读器
缘起
学习uniapp有一年多,前期做过一个同城项目,后面工作忙,没有继续深入学习。2020年由于疫情的缘故,在家搁置时间过长,期间父亲大人迷上了小说,我就去网上找各种破解版小说APP给他。刚开始还好,看着看着软件强制更新了,就又给他找其他的破解APP,看一段时间又更新了。。。周而复始,后来就想为什么不自己弄一个呢,于是就有了今天这个项目。
主要功能
我主张一切从简,小说阅读器的主要功能:能看,能搜。无论是三岁小孩,还是八十老妪,打开就能懂如何使用。
界面设计
业余前端,不追求页面的极致,能看就行。
- 主页
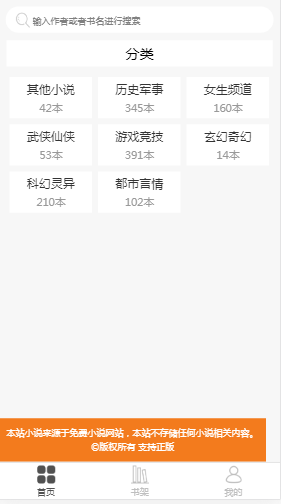
- 分类页
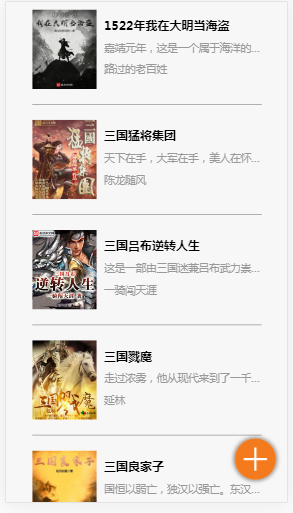
- 书籍详情页
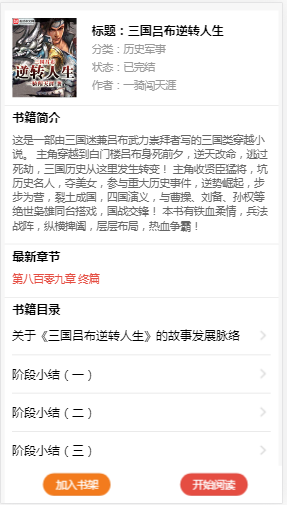
- 书籍阅读页



- 书架页
- 我的页
 我的页没有实质性功能,没有登录操作。
我的页没有实质性功能,没有登录操作。
制作期间去uniapp的插件市场观摩了其他大佬做的小说阅读器,本来是不想重复造轮子的,使用过程中发现了一些BUG,我无法解决,后来不得不自己造轮子了。
程序开发
鉴于自己都是前端小白,努力做到页面结构划分清晰,让人看着不乱,能自己扩展。所以组件我选用了官方组件,css纯手写。


 页面内部js也有注释说明,能详尽详。
页面内部js也有注释说明,能详尽详。
API接口说明
页面都是异步请求加载数据的,下面列出所有界面需要的接口。
首页
- 获取分类小说总数接口
getcategorycount
返回示例
{"msg":"操作成功","code":200,"cclist":[{"count":42,"category":"其他小说"},{"count":345,"category":"历史军事"},{"count":160,"category":"女生频道"},{"count":53,"category":"武侠仙侠"},{"count":391,"category":"游戏竞技"},{"count":14,"category":"玄幻奇幻"},{"count":210,"category":"科幻灵异"},{"count":102,"category":"都市言情"}]}
- 搜索接口
searchBook
返回示例
{"msg":"操作成功","booklist":[{"create_time":"2020-05-10 10:40:55","fiction_url":"ww.abc.com","author":"糖衣古典","description":"……","id":1252,"title":"盗墓者传奇:月夜鬼吹灯","f_type":"科幻灵异","book_img":"24340.jpg","f_status":"连载中"}],"code":200}
小说分类页接口
- 获取某分类下有多少本小说
getbooklist
返回示例
{"msg":"操作成功","code":200,"totalpages":1,"bookList":[{"id":1360,"title":"诡秘之主","author":"爱潜水的乌贼","description":"明依旧照耀,神秘从未远离,这是一段“愚者”的传说。","updateTime":null,"createTime":"2020-05-11 11:00:18","wordNumber":null,"bookImg":"1949.gif","fictionUrl":"https://www.abcw.com/index.html","fstatus":"连载中","ftype":"玄幻奇幻"}]}
书籍详情页接口
- 获取书籍详情
getbookinfo?fictionid=1351
{"msg":"操作成功","code":200,"bookData":{"id":1351,"title":"三国美人志","author":"最后的茄子","description":"书籍描述","updateTime":null,"createTime":"2020-05-10 17:05:15","wordNumber":null,"bookImg":"woshitupian","fictionUrl":"www.xsddss.com","fstatus":"已完结","ftype":"游戏竞技"}}
- 获取章节目录
getchapterlist
{"msg":"操作成功","code":200,"chapterlist":[{"id":null,"fictionId":null,"chapterTitle":"第一章 穿越成陶松","content":null,"createDate":null,"chapterUrl":"www.xxx.com","corder":1}]
读书详情页接口
getcontent
{"msg":"操作成功","code":200,"content":"我是内容"}
以上是运行项目所需要的API接口,各位读者可根据自己的语言的特性,开发相关的API接口。
结语
经过半个月的努力,一套属于我自己的小说阅读器诞生了,uniapp可以打包成H5和APP。我自己买了个服务器,部署了H5端,运行了一段时间,自我感觉还好。1M的带宽,后台还要抓小说,正式站点就不放出来了。怕崩。
疑问:小说从哪里来?
百度 免费小说 会出来一堆网站,自己选一个反应快的界面不乱的广告少的网站进行抓取。 怎么抓取?
- 打包成APP的,可以参考uniapp插件里头的仔仔小说阅读器,直接前端抓取。
- 打包成H5形式的,有跨域问题,不能在前端抓取,需要有自己的后台进行抓。如果你会JAVA就用Java抓,会phython就用phython抓。 抓取技术Java我用的jsoup,会jquery就能分析出来界面结构。
采集之后的小说可以保存到自己的数据库中,这样页面基本是秒加载的。当然你可以不保存到库,页面打开的时候后台动态抓取,动态返回文章内容章节内容等。这样是做的一点好处就是:后台不用跑自动任务去更新小说章节;缺点:就是有点慢。目前我采用的是动态采集,孰优孰劣,自己取舍。
源码地址
MIT License
Copyright (c) 2020 寻找距离
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
举报
请认真填写举报原因,尽可能描述详细。
请选择举报类型
误判申诉
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。
尝试更多
代码解读
代码找茬
代码优化