代码拉取完成,页面将自动刷新
Fork 仓库
加载中
确定同步?
同步操作将从 iswbm/GolangCodingTime 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149
# coding:utf-8
import os
# import commands
import subprocess
import platform
from git import Repo
osName = platform.system()
repo_path ='.'
if (osName == 'Windows'):
repo_path = 'E:\\MING-Git\\GolangCodingTime'
blog_path = 'E:\\MING-Git\GolangCodingTime\\source'
index_path = 'E:\\MING-Git\\GolangCodingTime\\README.md'
elif (osName == 'Darwin'):
repo_path = '/Users/MING/Github/GolangCodingTime/'
blog_path = '/Users/MING/Github/GolangCodingTime/source'
index_path = '/Users/MING/Github/GolangCodingTime/README.md'
#repo = Repo.init(path=repo_path)
#if not repo.is_dirty():
# # 没有文件变更
# os._exit(0)
base_link = "http://golang.iswbm.com/en/latest/"
readme_header = '''

<p align="center">
<img src='https://img.shields.io/badge/language-Python-blue.svg' alt="Build Status">
<img src='https://img.shields.io/badge/framwork-Sphinx-green.svg'>
<a href='https://www.zhihu.com/people/wongbingming'><img src='https://img.shields.io/badge/dynamic/json?color=0084ff&logo=zhihu&label=%E7%8E%8B%E7%82%B3%E6%98%8E&query=%24.data.totalSubs&url=https%3A%2F%2Fapi.spencerwoo.com%2Fsubstats%2F%3Fsource%3Dzhihu%26queryKey%3Dwongbingming'></a>
<a href='https://juejin.im/user/5b08d982f265da0db3502c55'><img src='https://img.shields.io/badge/掘金-2481-blue'></a>
<a href='http://image.iswbm.com/20200607114246.png'><img src='http://img.shields.io/badge/%E5%85%AC%E4%BC%97%E5%8F%B7-30k+-brightgreen'></a>
</p>
## [项目主页](http://python.iswbm.com/)
在线阅读:[Python 编程时光](http://python.iswbm.com/)
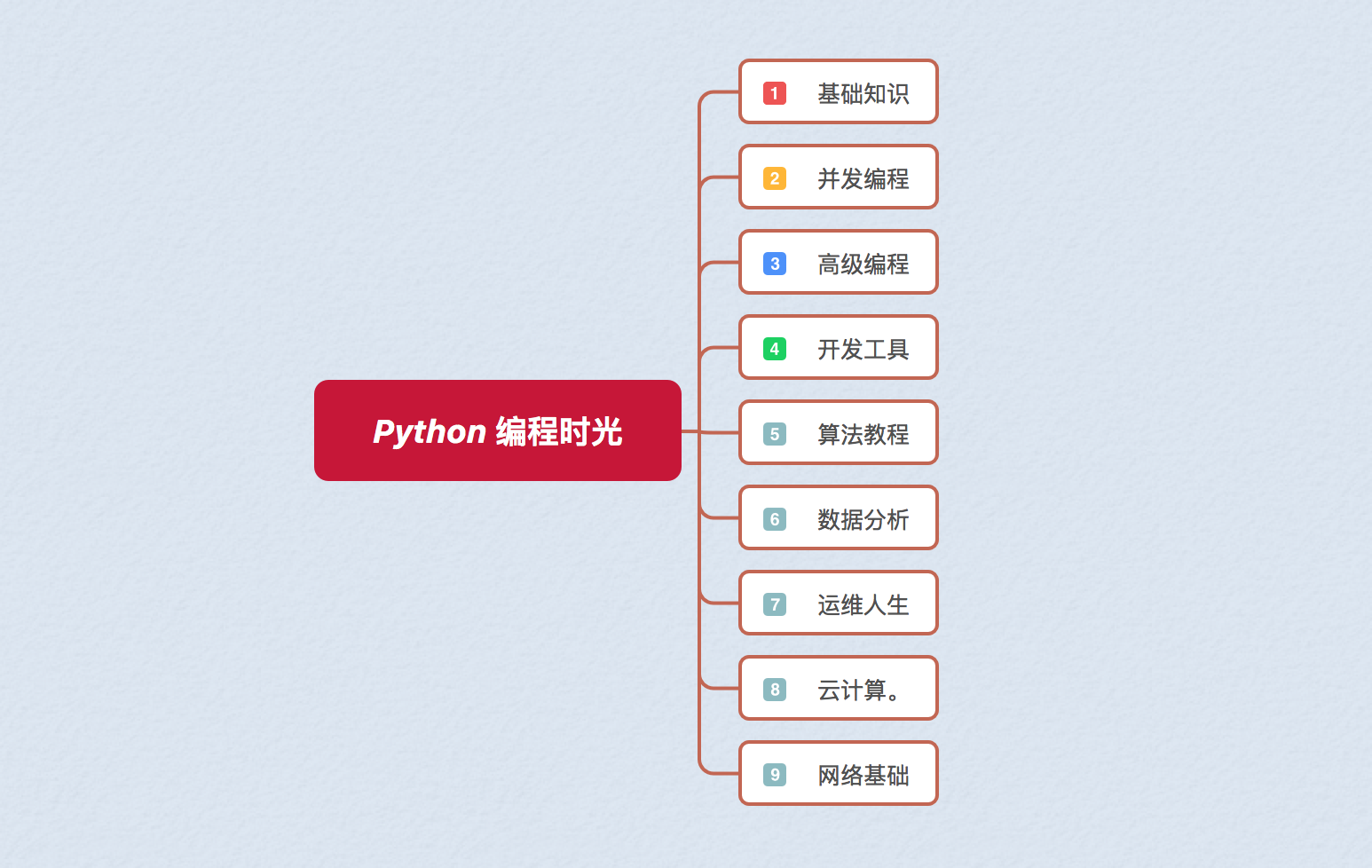
## 文章结构
'''
readme_tooter = '''
---

'''
def get_file_info(filename):
with open(filename, 'r', encoding="utf-8") as file:
first_line = file.readline().replace("#", "").strip()
return first_line.split(' ', 1)
def make_line(chapter, file):
page_name, _ = os.path.splitext(file)
(index, title) = get_file_info(file)
url = base_link + chapter + "/" + page_name + ".html"
item_list = ["-", index, "[{}]({})\n".format(title, url)]
return " ".join(item_list)
def render_index_page(index_info):
'''
生成 readme.md 索引文件,包含所有文件目录
'''
# 重新排序
index_info = sorted(index_info.items(), key=lambda item:item[0], reverse=False)
# 写入文件
with open(index_path, 'w+', encoding="utf-8") as file:
file.write(readme_header)
for chp, info in index_info:
chp_name = info["name"]
file.write("## " + chp_name + "\n")
for line in info["contents"]:
file.write(line)
file.write("\n")
file.write(readme_tooter)
def convert_md5_to_rst(file):
'''
转换格式:md5转换成rst
'''
(filename, extension) = os.path.splitext(file)
convert_cmd = 'pandoc -V mainfont="SimSun" -f markdown -t rst {md_file} -o {rst_file}'.format(
md_file=filename+'.md', rst_file=filename+'.rst'
)
# status, output = commands.getstatusoutput(convert_cmd)
status = subprocess.call(convert_cmd.split(" "))
if status != 0:
print("命令执行失败: " + convert_cmd)
os._exit(1)
if status == 0:
print(file + ' 处理完成')
else:
print(file + '处理失败')
def get_all_dir():
'''
获取所有的目录
'''
dir_list = []
file_list = os.listdir(blog_path)
for item in file_list:
abs_path = os.path.join(blog_path, item)
if os.path.isdir(abs_path):
dir_list.append(abs_path)
return dir_list
def init_index_info():
'''
初始化索引
'''
index_info = {}
chapter_dir = os.path.join(blog_path, "chapters")
os.chdir(chapter_dir)
for file in os.listdir(chapter_dir):
name, _ = os.path.splitext(file)
with open(file, 'r', encoding="utf-8") as f:
chapter_name = f.readlines()[1].strip()
index_info[name.replace("p", "")] = {"name": chapter_name, "contents": []}
return index_info
def main(index_info):
for folder in get_all_dir():
os.chdir(folder)
chapter = os.path.split(folder)[1]
all_file = os.listdir(folder)
all_md_file = sorted([file for file in all_file if file.endswith('md')])
for file in all_md_file:
line = make_line(chapter, file)
index_info[chapter.replace("c", "")]["contents"].append(line)
convert_md5_to_rst(file)
if __name__ == '__main__':
index_info = init_index_info()
main(index_info)
# render_index_page(index_info)
print("OK")
Loading...
举报
请认真填写举报原因,尽可能描述详细。
请选择举报类型
误判申诉
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。
尝试更多
代码解读
代码找茬
代码优化