代码拉取完成,页面将自动刷新
Loading...


Spring Cloud Sleuth
Spring Cloud Sleuth is a distributed tracing tool for Spring Cloud. It borrows from Dapper, Zipkin, and HTrace.
Quick Start
Add sleuth to the classpath of a Spring Boot application (see “Adding Sleuth to the Project” for Maven and Gradle examples), and you can see the correlation data being collected in logs, as long as you are logging requests.
For example, consider the following HTTP handler:
@RestController
public class DemoController {
private static Logger log = LoggerFactory.getLogger(DemoController.class);
@RequestMapping("/")
public String home() {
log.info("Handling home");
...
return "Hello World";
}
}
If you add that handler to a controller, you can see the calls to home() being traced in the logs and in Zipkin, if Zipkin is configured.
|
Note
|
Instead of logging the request in the handler explicitly, you
could set logging.level.org.springframework.web.servlet.DispatcherServlet=DEBUG.
|
|
Note
|
Set spring.application.name=myService (for instance) to see the service name as well as the trace and span IDs.
|
|
Important
|
If you use Zipkin, configure the probability of spans exported by setting spring.sleuth.sampler.probability
(default: 0.1, which is 10 percent). Otherwise, you might think that Sleuth is not working be cause it omits some spans.
|
Introduction
Spring Cloud Sleuth implements a distributed tracing solution for Spring Cloud.
Terminology
Spring Cloud Sleuth borrows Dapper’s terminology.
Span: The basic unit of work. For example, sending an RPC is a new span, as is sending a response to an RPC. Spans are identified by a unique 64-bit ID for the span and another 64-bit ID for the trace the span is a part of. Spans also have other data, such as descriptions, timestamped events, key-value annotations (tags), the ID of the span that caused them, and process IDs (normally IP addresses).
Spans can be started and stopped, and they keep track of their timing information. Once you create a span, you must stop it at some point in the future.
|
Tip
|
The initial span that starts a trace is called a root span. The value of the ID
of that span is equal to the trace ID.
|
Trace: A set of spans forming a tree-like structure.
For example, if you run a distributed big-data store, a trace might be formed by a PUT request.
Annotation: Used to record the existence of an event in time. With Brave instrumentation, we no longer need to set special events for Zipkin to understand who the client and server are, where the request started, and where it ended. For learning purposes, however, we mark these events to highlight what kind of an action took place.
-
cs: Client Sent. The client has made a request. This annotation indicates the start of the span.
-
sr: Server Received: The server side got the request and started processing it. Subtracting the
cstimestamp from this timestamp reveals the network latency. -
ss: Server Sent. Annotated upon completion of request processing (when the response got sent back to the client). Subtracting the
srtimestamp from this timestamp reveals the time needed by the server side to process the request. -
cr: Client Received. Signifies the end of the span. The client has successfully received the response from the server side. Subtracting the
cstimestamp from this timestamp reveals the whole time needed by the client to receive the response from the server.
The following image shows how Span and Trace look in a system, together with the Zipkin annotations:

Each color of a note signifies a span (there are seven spans - from A to G). Consider the following note:
Trace Id = X
Span Id = D
Client Sent
This note indicates that the current span has Trace Id set to X and Span Id set to D.
Also, the Client Sent event took place.
The following image shows how parent-child relationships of spans look:

Purpose
The following sections refer to the example shown in the preceding image.
Distributed Tracing with Zipkin
This example has seven spans. If you go to traces in Zipkin, you can see this number in the second trace, as shown in the following image:

However, if you pick a particular trace, you can see four spans, as shown in the following image:

|
Note
|
When you pick a particular trace, you see merged spans. That means that, if there were two spans sent to Zipkin with Server Received and Server Sent or Client Received and Client Sent annotations, they are presented as a single span. |
Why is there a difference between the seven and four spans in this case?
-
One span comes from the
http:/startspan. It has the Server Received (sr) and Server Sent (ss) annotations. -
Two spans come from the RPC call from
service1toservice2to thehttp:/fooendpoint. The Client Sent (cs) and Client Received (cr) events took place on theservice1side. Server Received (sr) and Server Sent (ss) events took place on theservice2side. These two spans form one logical span related to an RPC call. -
Two spans come from the RPC call from
service2toservice3to thehttp:/barendpoint. The Client Sent (cs) and Client Received (cr) events took place on theservice2side. The Server Received (sr) and Server Sent (ss) events took place on theservice3side. These two spans form one logical span related to an RPC call. -
Two spans come from the RPC call from
service2toservice4to thehttp:/bazendpoint. The Client Sent (cs) and Client Received (cr) events took place on theservice2side. Server Received (sr) and Server Sent (ss) events took place on theservice4side. These two spans form one logical span related to an RPC call.
So, if we count the physical spans, we have one from http:/start, two from service1 calling service2, two from service2
calling service3, and two from service2 calling service4. In sum, we have a total of seven spans.
Logically, we see the information of four total Spans because we have one span related to the incoming request
to service1 and three spans related to RPC calls.
Visualizing errors
Zipkin lets you visualize errors in your trace. When an exception was thrown and was not caught, we set proper tags on the span, which Zipkin can then properly colorize. You could see in the list of traces one trace that is red. That appears because an exception was thrown.
If you click that trace, you see a similar picture, as follows:
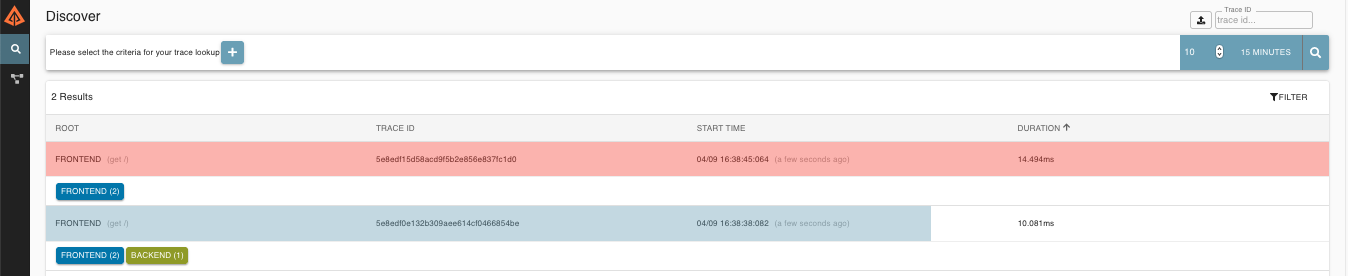
If you then click on one of the spans, you see the following
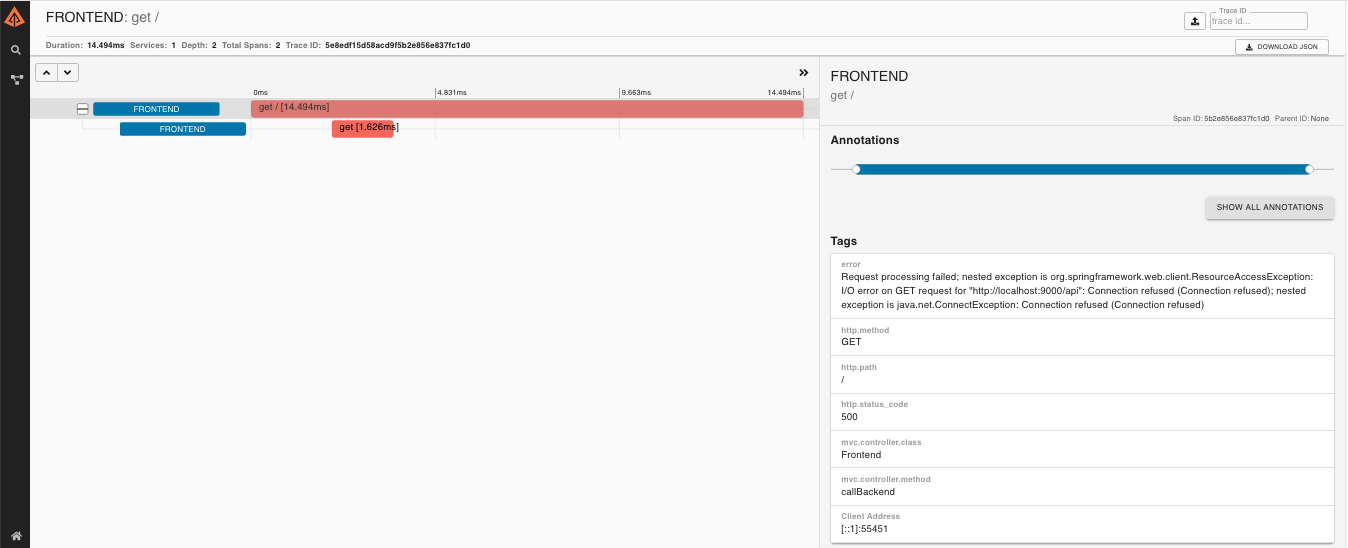
The span shows the reason for the error and the whole stack trace related to it.
Distributed Tracing with Brave
Starting with version 2.0.0, Spring Cloud Sleuth uses Brave as the tracing library.
Consequently, Sleuth no longer takes care of storing the context but delegates that work to Brave.
Due to the fact that Sleuth had different naming and tagging conventions than Brave, we decided to follow Brave’s conventions from now on.
However, if you want to use the legacy Sleuth approaches, you can set the spring.sleuth.http.legacy.enabled property to true.
Live examples

Click the Pivotal Web Services icon to see it live!Click the Pivotal Web Services icon to see it live!
The dependency graph in Zipkin should resemble the following image:

Click the Pivotal Web Services icon to see it live!Click the Pivotal Web Services icon to see it live!
Log correlation
When using grep to read the logs of those four applications by scanning for a trace ID equal to (for example) 2485ec27856c56f4, you get output resembling the following:
service1.log:2016-02-26 11:15:47.561 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Hello from service1. Calling service2
service2.log:2016-02-26 11:15:47.710 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Hello from service2. Calling service3 and then service4
service3.log:2016-02-26 11:15:47.895 INFO [service3,2485ec27856c56f4,1210be13194bfe5,true] 68060 --- [nio-8083-exec-1] i.s.c.sleuth.docs.service3.Application : Hello from service3
service2.log:2016-02-26 11:15:47.924 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service3 [Hello from service3]
service4.log:2016-02-26 11:15:48.134 INFO [service4,2485ec27856c56f4,1b1845262ffba49d,true] 68061 --- [nio-8084-exec-1] i.s.c.sleuth.docs.service4.Application : Hello from service4
service2.log:2016-02-26 11:15:48.156 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service4 [Hello from service4]
service1.log:2016-02-26 11:15:48.182 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Got response from service2 [Hello from service2, response from service3 [Hello from service3] and from service4 [Hello from service4]]
If you use a log aggregating tool (such as Kibana, Splunk, and others), you can order the events that took place. An example from Kibana would resemble the following image:
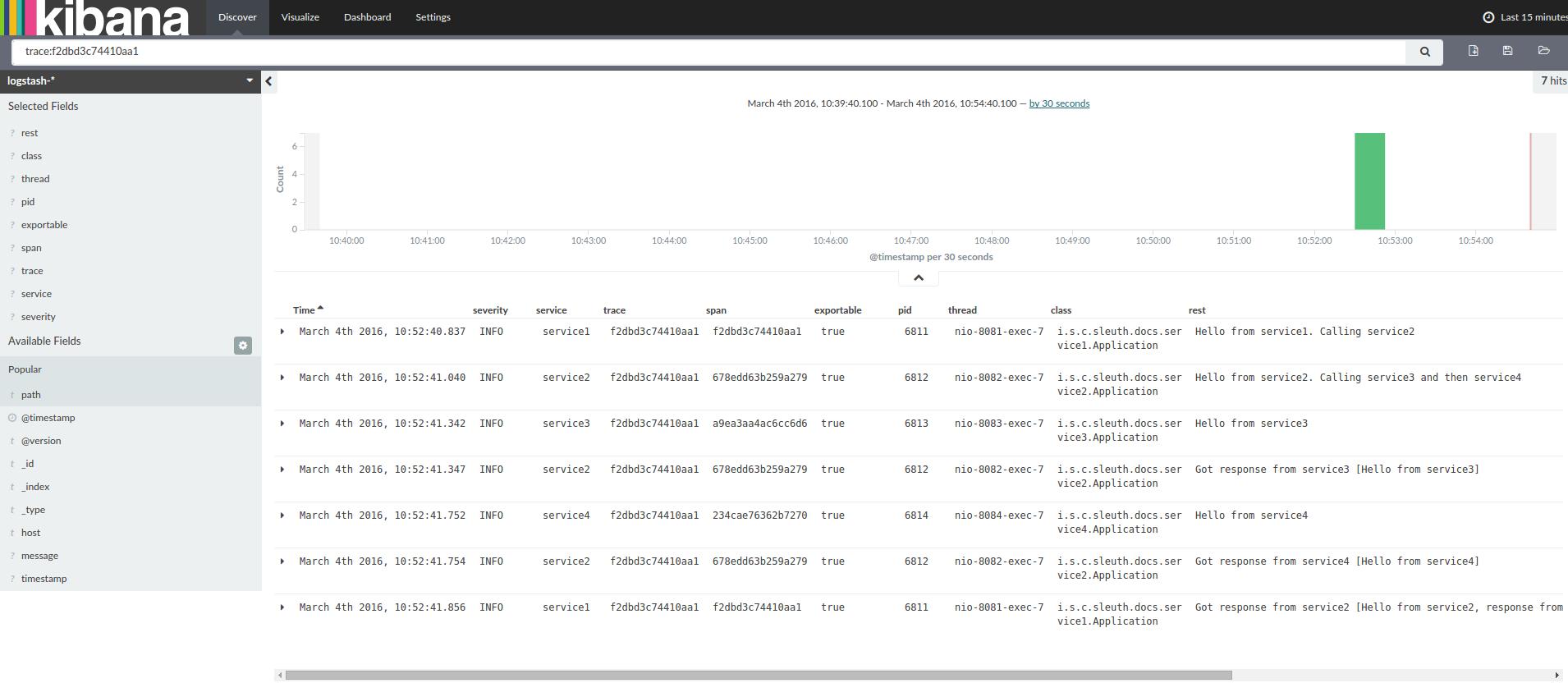
If you want to use Logstash, the following listing shows the Grok pattern for Logstash:
filter {
# pattern matching logback pattern
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
}
|
Note
|
If you want to use Grok together with the logs from Cloud Foundry, you have to use the following pattern: |
filter {
# pattern matching logback pattern
grok {
match => { "message" => "(?m)OUT\s+%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
}
JSON Logback with Logstash
Often, you do not want to store your logs in a text file but in a JSON file that Logstash can immediately pick.
To do so, you have to do the following (for readability, we pass the dependencies in the groupId:artifactId:version notation).
Dependencies Setup
-
Ensure that Logback is on the classpath (
ch.qos.logback:logback-core). -
Add Logstash Logback encode. For example, to use version
4.6, addnet.logstash.logback:logstash-logback-encoder:4.6.
Logback Setup
Consider the following example of a Logback configuration file (named logback-spring.xml).
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<!-- Example for logging into the build folder of your project -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>
<!-- You can override this to have a custom pattern -->
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<!-- Appender to log to console -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<!-- Minimum logging level to be presented in the console logs-->
<level>DEBUG</level>
</filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file -->
<appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file in a JSON format -->
<appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}.json</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"parent": "%X{X-B3-ParentSpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="console"/>
<!-- uncomment this to have also JSON logs -->
<!--<appender-ref ref="logstash"/>-->
<!--<appender-ref ref="flatfile"/>-->
</root>
</configuration>
That Logback configuration file:
-
Logs information from the application in a JSON format to a
build/${spring.application.name}.jsonfile. -
Has commented out two additional appenders: console and standard log file.
-
Has the same logging pattern as the one presented in the previous section.
|
Note
|
If you use a custom logback-spring.xml, you must pass the spring.application.name in the bootstrap rather than the application property file.
Otherwise, your custom logback file does not properly read the property.
|
Propagating Span Context
The span context is the state that must get propagated to any child spans across process boundaries. Part of the Span Context is the Baggage. The trace and span IDs are a required part of the span context. Baggage is an optional part.
Baggage is a set of key:value pairs stored in the span context.
Baggage travels together with the trace and is attached to every span.
Spring Cloud Sleuth understands that a header is baggage-related if the HTTP header is prefixed with baggage- and, for messaging, it starts with baggage_.
|
Important
|
There is currently no limitation of the count or size of baggage items. However, keep in mind that too many can decrease system throughput or increase RPC latency. In extreme cases, too much baggage can crash the application, due to exceeding transport-level message or header capacity. |
The following example shows setting baggage on a span:
Span initialSpan = this.tracer.nextSpan().name("span").start();
ExtraFieldPropagation.set(initialSpan.context(), "foo", "bar");
ExtraFieldPropagation.set(initialSpan.context(), "UPPER_CASE", "someValue");
Baggage versus Span Tags
Baggage travels with the trace (every child span contains the baggage of its parent). Zipkin has no knowledge of baggage and does not receive that information.
|
Important
|
Starting from Sleuth 2.0.0 you have to pass the baggage key names explicitly in your project configuration. Read more about that setup here |
Tags are attached to a specific span. In other words, they are presented only for that particular span. However, you can search by tag to find the trace, assuming a span having the searched tag value exists.
If you want to be able to lookup a span based on baggage, you should add a corresponding entry as a tag in the root span.
|
Important
|
The span must be in scope. |
The following listing shows integration tests that use baggage:
The setup
spring.sleuth:
baggage-keys:
- baz
- bizarrecase
propagation-keys:
- foo
- upper_case
The code
initialSpan.tag("foo",
ExtraFieldPropagation.get(initialSpan.context(), "foo"));
initialSpan.tag("UPPER_CASE",
ExtraFieldPropagation.get(initialSpan.context(), "UPPER_CASE"));
Adding Sleuth to the Project
This section addresses how to add Sleuth to your project with either Maven or Gradle.
|
Important
|
To ensure that your application name is properly displayed in Zipkin, set the spring.application.name property in bootstrap.yml.
|
Only Sleuth (log correlation)
If you want to use only Spring Cloud Sleuth without the Zipkin integration, add the spring-cloud-starter-sleuth module to your project.
The following example shows how to add Sleuth with Maven:
Maven
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${release.train.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
-
We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself.
-
Add the dependency to
spring-cloud-starter-sleuth.
The following example shows how to add Sleuth with Gradle:
Gradle
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies { (2)
compile "org.springframework.cloud:spring-cloud-starter-sleuth"
}
-
We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself.
-
Add the dependency to
spring-cloud-starter-sleuth.
Sleuth with Zipkin via HTTP
If you want both Sleuth and Zipkin, add the spring-cloud-starter-zipkin dependency.
The following example shows how to do so for Maven:
Maven
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${release.train.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
-
We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself.
-
Add the dependency to
spring-cloud-starter-zipkin.
The following example shows how to do so for Gradle:
Gradle
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies { (2)
compile "org.springframework.cloud:spring-cloud-starter-zipkin"
}
-
We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself.
-
Add the dependency to
spring-cloud-starter-zipkin.
Sleuth with Zipkin over RabbitMQ or Kafka
If you want to use RabbitMQ or Kafka instead of HTTP, add the spring-rabbit or spring-kafka dependency.
The default destination name is zipkin.
If using Kafka, you must set the property spring.zipkin.sender.type property accordingly:
spring.zipkin.sender.type: kafka
|
Caution
|
spring-cloud-sleuth-stream is deprecated and incompatible with these destinations.
|
If you want Sleuth over RabbitMQ, add the spring-cloud-starter-zipkin and spring-rabbit
dependencies.
The following example shows how to do so for Gradle:
Maven
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${release.train.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency> (3)
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
-
We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself.
-
Add the dependency to
spring-cloud-starter-zipkin. That way, all nested dependencies get downloaded. -
To automatically configure RabbitMQ, add the
spring-rabbitdependency.
Gradle
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-starter-zipkin" (2)
compile "org.springframework.amqp:spring-rabbit" (3)
}
-
We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself.
-
Add the dependency to
spring-cloud-starter-zipkin. That way, all nested dependencies get downloaded. -
To automatically configure RabbitMQ, add the
spring-rabbitdependency.
Overriding the auto-configuration of Zipkin
Spring Cloud Sleuth supports sending traces to multiple tracing systems as of version 2.1.0.
In order to get this to work, every tracing system needs to have a Reporter<Span> and Sender.
If you want to override the provided beans you need to give them a specific name.
To do this you can use respectively ZipkinAutoConfiguration.REPORTER_BEAN_NAME and ZipkinAutoConfiguration.SENDER_BEAN_NAME.
Unresolved directive in intro.adoc - include::../../../spring-cloud-sleuth-zipkin/src/test/java/org/springframework/cloud/sleuth/zipkin2/ZipkinAutoConfigurationTests.java[tags=override_default_beans,indent=0]
Additional Resources
You can watch a video of Reshmi Krishna and Marcin Grzejszczak talking about Spring Cloud Sleuth and Zipkin by clicking here.
You can check different setups of Sleuth and Brave in the openzipkin/sleuth-webmvc-example repository.
Features
-
Adds trace and span IDs to the Slf4J MDC, so you can extract all the logs from a given trace or span in a log aggregator, as shown in the following example logs:
2016-02-02 15:30:57.902 INFO [bar,6bfd228dc00d216b,6bfd228dc00d216b,false] 23030 --- [nio-8081-exec-3] ... 2016-02-02 15:30:58.372 ERROR [bar,6bfd228dc00d216b,6bfd228dc00d216b,false] 23030 --- [nio-8081-exec-3] ... 2016-02-02 15:31:01.936 INFO [bar,46ab0d418373cbc9,46ab0d418373cbc9,false] 23030 --- [nio-8081-exec-4] ...
Notice the
[appname,traceId,spanId,exportable]entries from the MDC:-
spanId: The ID of a specific operation that took place. -
appname: The name of the application that logged the span. -
traceId: The ID of the latency graph that contains the span. -
exportable: Whether the log should be exported to Zipkin. When would you like the span not to be exportable? When you want to wrap some operation in a Span and have it written to the logs only.
-
-
Provides an abstraction over common distributed tracing data models: traces, spans (forming a DAG), annotations, and key-value annotations. Spring Cloud Sleuth is loosely based on HTrace but is compatible with Zipkin (Dapper).
-
Sleuth records timing information to aid in latency analysis. By using sleuth, you can pinpoint causes of latency in your applications.
-
Sleuth is written to not log too much and to not cause your production application to crash. To that end, Sleuth:
-
Propagates structural data about your call graph in-band and the rest out-of-band.
-
Includes opinionated instrumentation of layers such as HTTP.
-
Includes a sampling policy to manage volume.
-
Can report to a Zipkin system for query and visualization.
-
-
Instruments common ingress and egress points from Spring applications (servlet filter, async endpoints, rest template, scheduled actions, message channels, Zuul filters, and Feign client).
-
Sleuth includes default logic to join a trace across HTTP or messaging boundaries. For example, HTTP propagation works over Zipkin-compatible request headers.
-
Sleuth can propagate context (also known as baggage) between processes. Consequently, if you set a baggage element on a Span, it is sent downstream to other processes over either HTTP or messaging.
-
Provides a way to create or continue spans and add tags and logs through annotations.
-
If
spring-cloud-sleuth-zipkinis on the classpath, the app generates and collects Zipkin-compatible traces. By default, it sends them over HTTP to a Zipkin server on localhost (port 9411). You can configure the location of the service by settingspring.zipkin.baseUrl.-
If you depend on
spring-rabbit, your app sends traces to a RabbitMQ broker instead of HTTP. -
If you depend on
spring-kafka, and setspring.zipkin.sender.type: kafka, your app sends traces to a Kafka broker instead of HTTP.
-
|
Caution
|
spring-cloud-sleuth-stream is deprecated and should no longer be used.
|
-
Spring Cloud Sleuth is OpenTracing compatible.
|
Important
|
If you use Zipkin, configure the probability of spans exported by setting spring.sleuth.sampler.probability
(default: 0.1, which is 10 percent). Otherwise, you might think that Sleuth is not working be cause it omits some spans.
|
|
Note
|
The SLF4J MDC is always set and logback users immediately see the trace and span IDs in logs per the example
shown earlier.
Other logging systems have to configure their own formatter to get the same result.
The default is as follows:
logging.pattern.level set to %5p [${spring.zipkin.service.name:${spring.application.name:-}},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}]
(this is a Spring Boot feature for logback users).
If you do not use SLF4J, this pattern is NOT automatically applied.
|
Building
Basic Compile and Test
To build the source you will need to install JDK 1.7.
Spring Cloud uses Maven for most build-related activities, and you should be able to get off the ground quite quickly by cloning the project you are interested in and typing
$ ./mvnw install
|
Note
|
You can also install Maven (>=3.3.3) yourself and run the mvn command
in place of ./mvnw in the examples below. If you do that you also
might need to add -P spring if your local Maven settings do not
contain repository declarations for spring pre-release artifacts.
|
|
Note
|
Be aware that you might need to increase the amount of memory
available to Maven by setting a MAVEN_OPTS environment variable with
a value like -Xmx512m -XX:MaxPermSize=128m. We try to cover this in
the .mvn configuration, so if you find you have to do it to make a
build succeed, please raise a ticket to get the settings added to
source control.
|
For hints on how to build the project look in .travis.yml if there
is one. There should be a "script" and maybe "install" command. Also
look at the "services" section to see if any services need to be
running locally (e.g. mongo or rabbit). Ignore the git-related bits
that you might find in "before_install" since they’re related to setting git
credentials and you already have those.
The projects that require middleware generally include a
docker-compose.yml, so consider using
Docker Compose to run the middeware servers
in Docker containers. See the README in the
scripts demo
repository for specific instructions about the common cases of mongo,
rabbit and redis.
|
Note
|
If all else fails, build with the command from .travis.yml (usually
./mvnw install).
|
Documentation
The spring-cloud-build module has a "docs" profile, and if you switch
that on it will try to build asciidoc sources from
src/main/asciidoc. As part of that process it will look for a
README.adoc and process it by loading all the includes, but not
parsing or rendering it, just copying it to ${main.basedir}
(defaults to ${basedir}, i.e. the root of the project). If there are
any changes in the README it will then show up after a Maven build as
a modified file in the correct place. Just commit it and push the change.
Working with the code
If you don’t have an IDE preference we would recommend that you use Spring Tools Suite or Eclipse when working with the code. We use the m2eclipse eclipse plugin for maven support. Other IDEs and tools should also work without issue as long as they use Maven 3.3.3 or better.
Importing into eclipse with m2eclipse
We recommend the m2eclipse eclipse plugin when working with eclipse. If you don’t already have m2eclipse installed it is available from the "eclipse marketplace".
|
Note
|
Older versions of m2e do not support Maven 3.3, so once the
projects are imported into Eclipse you will also need to tell
m2eclipse to use the right profile for the projects. If you
see many different errors related to the POMs in the projects, check
that you have an up to date installation. If you can’t upgrade m2e,
add the "spring" profile to your settings.xml. Alternatively you can
copy the repository settings from the "spring" profile of the parent
pom into your settings.xml.
|
Importing into eclipse without m2eclipse
If you prefer not to use m2eclipse you can generate eclipse project metadata using the following command:
$ ./mvnw eclipse:eclipse
The generated eclipse projects can be imported by selecting import existing projects
from the file menu.
|
Important
|
Spring Cloud Sleuth uses two different versions of language level. Java 1.7 is used for main sources, and
Java 1.8 is used for tests. When importing your project to an IDE, you should activate the ide Maven profile to turn on
Java 1.8 for both main and test sources. You MUST NOT use Java 1.8 features in the main sources. If you do
so, your app breaks during the Maven build.
|
Contributing
Spring Cloud is released under the non-restrictive Apache 2.0 license, and follows a very standard Github development process, using Github tracker for issues and merging pull requests into master. If you want to contribute even something trivial please do not hesitate, but follow the guidelines below.
Sign the Contributor License Agreement
Before we accept a non-trivial patch or pull request we will need you to sign the Contributor License Agreement. Signing the contributor’s agreement does not grant anyone commit rights to the main repository, but it does mean that we can accept your contributions, and you will get an author credit if we do. Active contributors might be asked to join the core team, and given the ability to merge pull requests.
Code of Conduct
This project adheres to the Contributor Covenant code of conduct. By participating, you are expected to uphold this code. Please report unacceptable behavior to spring-code-of-conduct@pivotal.io.
Code Conventions and Housekeeping
None of these is essential for a pull request, but they will all help. They can also be added after the original pull request but before a merge.
-
Use the Spring Framework code format conventions. If you use Eclipse you can import formatter settings using the
eclipse-code-formatter.xmlfile from the Spring Cloud Build project. If using IntelliJ, you can use the Eclipse Code Formatter Plugin to import the same file. -
Make sure all new
.javafiles to have a simple Javadoc class comment with at least an@authortag identifying you, and preferably at least a paragraph on what the class is for. -
Add the ASF license header comment to all new
.javafiles (copy from existing files in the project) -
Add yourself as an
@authorto the .java files that you modify substantially (more than cosmetic changes). -
Add some Javadocs and, if you change the namespace, some XSD doc elements.
-
A few unit tests would help a lot as well — someone has to do it.
-
If no-one else is using your branch, please rebase it against the current master (or other target branch in the main project).
-
When writing a commit message please follow these conventions, if you are fixing an existing issue please add
Fixes gh-XXXXat the end of the commit message (where XXXX is the issue number).
Checkstyle
Spring Cloud Build comes with a set of checkstyle rules. You can find them in the spring-cloud-build-tools module. The most notable files under the module are:
spring-cloud-build-tools/
└── src ├── checkstyle │ └── checkstyle-suppressions.xml (3) └── main └── resources ├── checkstyle-header.txt (2) └── checkstyle.xml (1)
-
Default Checkstyle rules
-
File header setup
-
Default suppression rules
Checkstyle configuration
Checkstyle rules are disabled by default. To add checkstyle to your project just define the following properties and plugins.
pom.xml
<properties>
<maven-checkstyle-plugin.failsOnError>true</maven-checkstyle-plugin.failsOnError> (1)
<maven-checkstyle-plugin.failsOnViolation>true
</maven-checkstyle-plugin.failsOnViolation> (2)
<maven-checkstyle-plugin.includeTestSourceDirectory>true
</maven-checkstyle-plugin.includeTestSourceDirectory> (3)
</properties>
<build>
<plugins>
<plugin> (4)
<groupId>io.spring.javaformat</groupId>
<artifactId>spring-javaformat-maven-plugin</artifactId>
</plugin>
<plugin> (5)
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-checkstyle-plugin</artifactId>
</plugin>
</plugins>
<reporting>
<plugins>
<plugin> (5)
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-checkstyle-plugin</artifactId>
</plugin>
</plugins>
</reporting>
</build>
-
Fails the build upon Checkstyle errors
-
Fails the build upon Checkstyle violations
-
Checkstyle analyzes also the test sources
-
Add the Spring Java Format plugin that will reformat your code to pass most of the Checkstyle formatting rules
-
Add checkstyle plugin to your build and reporting phases
If you need to suppress some rules (e.g. line length needs to be longer), then it’s enough for you to define a file under ${project.root}/src/checkstyle/checkstyle-suppressions.xml with your suppressions. Example:
projectRoot/src/checkstyle/checkstyle-suppresions.xml
<?xml version="1.0"?> <!DOCTYPE suppressions PUBLIC "-//Puppy Crawl//DTD Suppressions 1.1//EN" "https://www.puppycrawl.com/dtds/suppressions_1_1.dtd"> <suppressions> <suppress files=".*ConfigServerApplication\.java" checks="HideUtilityClassConstructor"/> <suppress files=".*ConfigClientWatch\.java" checks="LineLengthCheck"/> </suppressions>
It’s advisable to copy the ${spring-cloud-build.rootFolder}/.editorconfig and ${spring-cloud-build.rootFolder}/.springformat to your project. That way, some default formatting rules will be applied. You can do so by running this script:
$ curl https://raw.githubusercontent.com/spring-cloud/spring-cloud-build/master/.editorconfig -o .editorconfig
$ touch .springformat
IDE setup
Intellij IDEA
In order to setup Intellij you should import our coding conventions, inspection profiles and set up the checkstyle plugin.
spring-cloud-build-tools/
└── src ├── checkstyle │ └── checkstyle-suppressions.xml (3) └── main └── resources ├── checkstyle-header.txt (2) ├── checkstyle.xml (1) └── intellij ├── Intellij_Project_Defaults.xml (4) └── Intellij_Spring_Boot_Java_Conventions.xml (5)
-
Default Checkstyle rules
-
File header setup
-
Default suppression rules
-
Project defaults for Intellij that apply most of Checkstyle rules
-
Project style conventions for Intellij that apply most of Checkstyle rules

Figure 1. Code style
Go to File → Settings → Editor → Code style. There click on the icon next to the Scheme section. There, click on the Import Scheme value and pick the Intellij IDEA code style XML option. Import the spring-cloud-build-tools/src/main/resources/intellij/Intellij_Spring_Boot_Java_Conventions.xml file.

Figure 2. Inspection profiles
Go to File → Settings → Editor → Inspections. There click on the icon next to the Profile section. There, click on the Import Profile and import the spring-cloud-build-tools/src/main/resources/intellij/Intellij_Project_Defaults.xml file.
Checkstyle
To have Intellij work with Checkstyle, you have to install the Checkstyle plugin. It’s advisable to also install the Assertions2Assertj to automatically convert the JUnit assertions

Go to File → Settings → Other settings → Checkstyle. There click on the + icon in the Configuration file section. There, you’ll have to define where the checkstyle rules should be picked from. In the image above, we’ve picked the rules from the cloned Spring Cloud Build repository. However, you can point to the Spring Cloud Build’s GitHub repository (e.g. for the checkstyle.xml : https://raw.githubusercontent.com/spring-cloud/spring-cloud-build/master/spring-cloud-build-tools/src/main/resources/checkstyle.xml). We need to provide the following variables:
-
checkstyle.header.file- please point it to the Spring Cloud Build’s,spring-cloud-build-tools/src/main/resources/checkstyle/checkstyle-header.txtfile either in your cloned repo or via thehttps://raw.githubusercontent.com/spring-cloud/spring-cloud-build/master/spring-cloud-build-tools/src/main/resources/checkstyle-header.txtURL. -
checkstyle.suppressions.file- default suppressions. Please point it to the Spring Cloud Build’s,spring-cloud-build-tools/src/checkstyle/checkstyle-suppressions.xmlfile either in your cloned repo or via thehttps://raw.githubusercontent.com/spring-cloud/spring-cloud-build/master/spring-cloud-build-tools/src/checkstyle/checkstyle-suppressions.xmlURL. -
checkstyle.additional.suppressions.file- this variable corresponds to suppressions in your local project. E.g. you’re working onspring-cloud-contract. Then point to theproject-root/src/checkstyle/checkstyle-suppressions.xmlfolder. Example forspring-cloud-contractwould be:/home/username/spring-cloud-contract/src/checkstyle/checkstyle-suppressions.xml.
|
Important
|
Remember to set the Scan Scope to All sources since we apply checkstyle rules for production and test sources.
|
Apache License
Version 2.0, January 2004
https://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
举报
请认真填写举报原因,尽可能描述详细。
请选择举报类型
误判申诉
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。
尝试更多
代码解读
代码找茬
代码优化