代码拉取完成,页面将自动刷新
Loading...
Horovod



Horovod is a distributed deep learning training framework for TensorFlow, Keras, PyTorch, and Apache MXNet. The goal of Horovod is to make distributed deep learning fast and easy to use.
![]()
Horovod is hosted by the LF AI & Data Foundation (LF AI & Data). If you are a company that is deeply committed to using open source technologies in artificial intelligence, machine, and deep learning, and want to support the communities of open source projects in these domains, consider joining the LF AI & Data Foundation. For details about who's involved and how Horovod plays a role, read the Linux Foundation announcement.
Contents
Documentation
Why Horovod?
The primary motivation for this project is to make it easy to take a single-GPU training script and successfully scale it to train across many GPUs in parallel. This has two aspects:
- How much modification does one have to make to a program to make it distributed, and how easy is it to run it?
- How much faster would it run in distributed mode?
Internally at Uber we found the MPI model to be much more straightforward and require far less code changes than previous solutions such as Distributed TensorFlow with parameter servers. Once a training script has been written for scale with Horovod, it can run on a single-GPU, multiple-GPUs, or even multiple hosts without any further code changes. See the Usage section for more details.
In addition to being easy to use, Horovod is fast. Below is a chart representing the benchmark that was done on 128 servers with 4 Pascal GPUs each connected by RoCE-capable 25 Gbit/s network:

Horovod achieves 90% scaling efficiency for both Inception V3 and ResNet-101, and 68% scaling efficiency for VGG-16. See Benchmarks to find out how to reproduce these numbers.
While installing MPI and NCCL itself may seem like an extra hassle, it only needs to be done once by the team dealing with infrastructure, while everyone else in the company who builds the models can enjoy the simplicity of training them at scale.
Install
To install Horovod:
- Install CMake
-
If you've installed TensorFlow from PyPI, make sure that the
g++-4.8.5org++-4.9or above is installed.If you've installed PyTorch from PyPI, make sure that the
g++-4.9or above is installed.If you've installed either package from Conda, make sure that the
gxx_linux-64Conda package is installed.
-
Install the
horovodpip package.To run on CPUs:
$ pip install horovod
To run on GPUs with NCCL:
$ HOROVOD_GPU_OPERATIONS=NCCL pip install horovod
For more details on installing Horovod with GPU support, read Horovod on GPU.
For the full list of Horovod installation options, read the Installation Guide.
If you want to use MPI, read Horovod with MPI.
If you want to use Conda, read Building a Conda environment with GPU support for Horovod.
If you want to use Docker, read Horovod in Docker.
To compile Horovod from source, follow the instructions in the Contributor Guide.
Concepts
Horovod core principles are based on MPI concepts such as size, rank, local rank, allreduce, allgather and, broadcast. See this page for more details.
Supported frameworks
See these pages for Horovod examples and best practices:
Usage
To use Horovod, make the following additions to your program:
- Run
hvd.init()to initialize Horovod.
-
Pin each GPU to a single process to avoid resource contention.
With the typical setup of one GPU per process, set this to local rank. The first process on the server will be allocated the first GPU, the second process will be allocated the second GPU, and so forth.
-
Scale the learning rate by the number of workers.
Effective batch size in synchronous distributed training is scaled by the number of workers. An increase in learning rate compensates for the increased batch size.
-
Wrap the optimizer in
hvd.DistributedOptimizer.The distributed optimizer delegates gradient computation to the original optimizer, averages gradients using allreduce or allgather, and then applies those averaged gradients.
-
Broadcast the initial variable states from rank 0 to all other processes.
This is necessary to ensure consistent initialization of all workers when training is started with random weights or restored from a checkpoint.
- Modify your code to save checkpoints only on worker 0 to prevent other workers from corrupting them.
Example using TensorFlow v1 (see the examples directory for full training examples):
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# Build model...
loss = ...
opt = tf.train.AdagradOptimizer(0.01 * hvd.size())
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
# Make training operation
train_op = opt.minimize(loss)
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd.rank() == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf.train.MonitoredTrainingSession(checkpoint_dir=checkpoint_dir,
config=config,
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Perform synchronous training.
mon_sess.run(train_op)
Running Horovod
The example commands below show how to run distributed training. See Run Horovod for more details, including RoCE/InfiniBand tweaks and tips for dealing with hangs.
-
To run on a machine with 4 GPUs:
$ horovodrun -np 4 -H localhost:4 python train.py
-
To run on 4 machines with 4 GPUs each:
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py
-
To run using Open MPI without the
horovodrunwrapper, see Running Horovod with Open MPI. -
To run in Docker, see Horovod in Docker.
-
To run in Kubernetes, see Kubeflow, MPI Operator, Helm Chart, FfDL, and Polyaxon.
-
To run on Spark, see Horovod on Spark.
-
To run on Ray, see Horovod on Ray.
-
To run in Singularity, see Singularity.
-
To run in a LSF HPC cluster (e.g. Summit), see LSF.
Gloo
Gloo is an open source collective communications library developed by Facebook.
Gloo comes included with Horovod, and allows users to run Horovod without requiring MPI to be installed.
For environments that have support both MPI and Gloo, you can choose to use Gloo at runtime by passing the --gloo argument to horovodrun:
$ horovodrun --gloo -np 2 python train.py
mpi4py
Horovod supports mixing and matching Horovod collectives with other MPI libraries, such as mpi4py, provided that the MPI was built with multi-threading support.
You can check for MPI multi-threading support by querying the hvd.mpi_threads_supported() function.
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Verify that MPI multi-threading is supported.
assert hvd.mpi_threads_supported()
from mpi4py import MPI
assert hvd.size() == MPI.COMM_WORLD.Get_size()
You can also initialize Horovod with an mpi4py sub-communicator, in which case each sub-communicator will run an independent Horovod training.
from mpi4py import MPI
import horovod.tensorflow as hvd
# Split COMM_WORLD into subcommunicators
subcomm = MPI.COMM_WORLD.Split(color=MPI.COMM_WORLD.rank % 2,
key=MPI.COMM_WORLD.rank)
# Initialize Horovod
hvd.init(comm=subcomm)
print('COMM_WORLD rank: %d, Horovod rank: %d' % (MPI.COMM_WORLD.rank, hvd.rank()))
Inference
Learn how to optimize your model for inference and remove Horovod operations from the graph here.
Tensor Fusion
One of the unique things about Horovod is its ability to interleave communication and computation coupled with the ability to batch small allreduce operations, which results in improved performance. We call this batching feature Tensor Fusion.
See here for full details and tweaking instructions.
Horovod Timeline
Horovod has the ability to record the timeline of its activity, called Horovod Timeline.
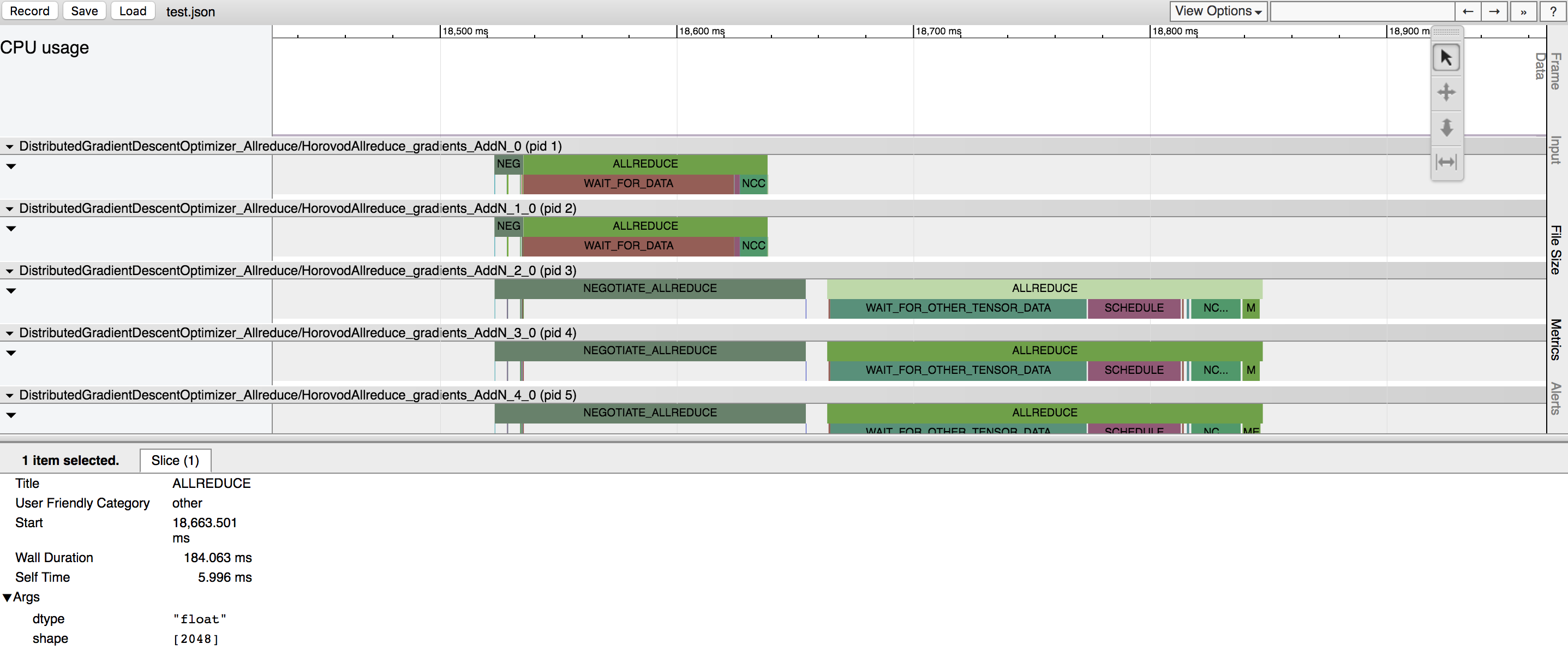
Use Horovod timeline to analyze Horovod performance. See here for full details and usage instructions.
Automated Performance Tuning
Selecting the right values to efficiently make use of Tensor Fusion and other advanced Horovod features can involve
a good amount of trial and error. We provide a system to automate this performance optimization process called
autotuning, which you can enable with a single command line argument to horovodrun.
See here for full details and usage instructions.
Guides
- Run distributed training in Microsoft Azure using Batch AI and Horovod.
- Distributed model training using Horovod.
Send us links to any user guides you want to publish on this site
Troubleshooting
See Troubleshooting and submit a ticket if you can't find an answer.
Citation
Please cite Horovod in your publications if it helps your research:
@article{sergeev2018horovod,
Author = {Alexander Sergeev and Mike Del Balso},
Journal = {arXiv preprint arXiv:1802.05799},
Title = {Horovod: fast and easy distributed deep learning in {TensorFlow}},
Year = {2018}
}
Publications
1. Sergeev, A., Del Balso, M. (2017) Meet Horovod: Uber’s Open Source Distributed Deep Learning Framework for TensorFlow. Retrieved from https://eng.uber.com/horovod/
2. Sergeev, A. (2017) Horovod - Distributed TensorFlow Made Easy. Retrieved from https://www.slideshare.net/AlexanderSergeev4/horovod-distributed-tensorflow-made-easy
3. Sergeev, A., Del Balso, M. (2018) Horovod: fast and easy distributed deep learning in TensorFlow. Retrieved from arXiv:1802.05799
References
The Horovod source code was based off the Baidu tensorflow-allreduce repository written by Andrew Gibiansky and Joel Hestness. Their original work is described in the article Bringing HPC Techniques to Deep Learning.
Getting Involved
- Community Slack for collaboration and discussion
- Horovod Announce for updates on the project
- Horovod Technical-Discuss for public discussion
Horovod
Copyright 2018 Uber Technologies, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
举报
请认真填写举报原因,尽可能描述详细。
请选择举报类型
误判申诉
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。
编辑仓库简介
简介内容
主页
尝试更多
代码解读
代码找茬
代码优化